U izradi.
U izradi.
U izradi.
4–6 minuta
Nakon što smo pripremili Raspberry Pi, ažurirali operativni sustav i postavili osnovne mrežne i sigurnosne postavke, vrijeme je za središnji dio projekta – instalaciju i osnovno podešavanje Pi-holea®. U ovom koraku Raspberry Pi prestaje biti “obično” Linux računalo i postaje središnji DNS poslužitelj koji filtrira mrežni promet i blokira reklame na razini cijele lokalne mreže.
Pi-hole® je dizajniran tako da se instalacija može obaviti vrlo jednostavno, putem jedne naredbe, ali iza tog procesa događa se niz važnih konfiguracijskih koraka koje je korisno razumjeti. Upravo zato ćemo ovdje proći instalaciju korak po korak i objasniti najvažnije odluke koje se donose tijekom početnog postavljanja.
Ovaj članak dio je projekta Pi-hole®, u kojem korak po korak implementiramo rješenje za blokiranje reklama na razini cijele mreže.
Više o projektu pročitajte ovdje.
Sadržaj članka
Sadržaj projekta
- Uvod: zašto blokirati reklame na razini cijele mreže
- Što je DNS i kako funkcionira DNS filtriranje
- Raspberry Pi kao DNS poslužitelj u kućnoj mreži
- Instalacija operativnog sustava na Raspberry Pi
- » Instalacija i osnovno podešavanje Pi-holea®
- Konfiguracija routera i/ili cloud gatewaya za Pi-hole®
- Kako testirati radi li Pi-hole ispravno
- Najčešći problem i kako ih riješiti
Instalacija Pi-holea®
Pi-hole® se instalira službenim instalacijskim skriptom koji se preuzima izravno s projekta. Ovo je važno jer osigurava da koristimo provjeren i ažuriran izvor.
Instalaciju pokrećemo sljedećom naredbom:
curl -sSL https://install.pi-hole.net | bashNakon pokretanja skripte započinje interaktivni instalacijski čarobnjak koji nas vodi kroz sve važne postavke. Prije svega čeka nas ekran dobrodošlice.
Iza njega, dolazi nam ekran za podršku projektu koji nam daje link do adrese na kojoj je moguće donirati novce za Pi-hole.
Odabir mrežnog sučelja
U prvom koraku Pi-hole® traži odabir mrežnog sučelja. Ako Raspberry Pi ima samo jednu aktivnu mrežnu vezu (najčešće Ethernet ili Wi-Fi), izbor je jednostavan.
Važno je odabrati sučelje preko kojeg uređaji u mreži komuniciraju s Raspberry Pi-jem, jer će se Pi-hole vezati upravo na to sučelje i slušati DNS upite.
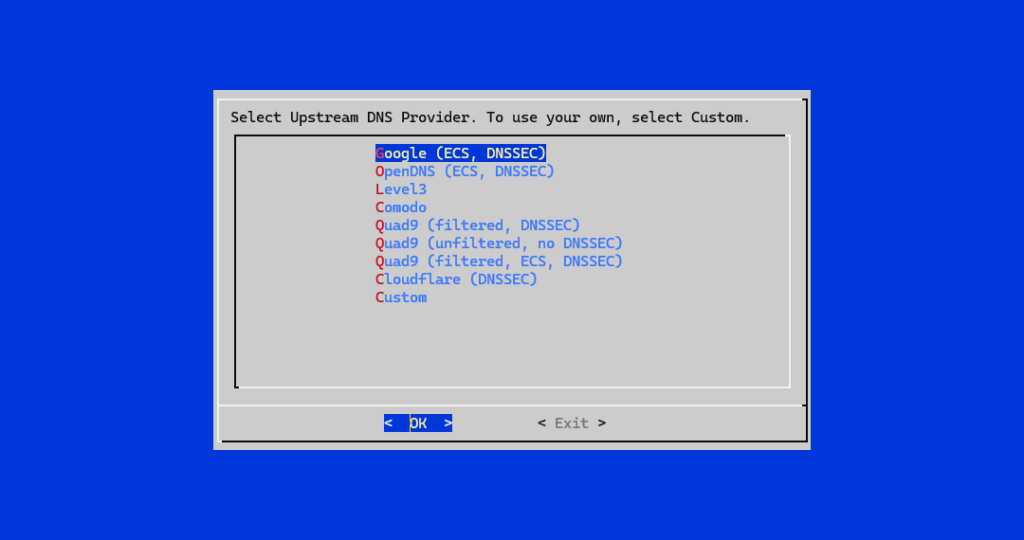
Odabir upstream DNS poslužitelja
Pi-hole® sam po sebi ne rješava DNS upite do kraja, već ih, ako nisu blokirani, prosljeđuje prema tzv. upstream DNS poslužitelju. Tijekom instalacije nudi se nekoliko popularnih opcija, poput:
- Cloudflare
- Google DNS
- OpenDNS
- Quad9
Koji god odabir napravili, Pi-hole® će i dalje obavljati filtriranje, dok će se stvarno razrješavanje domena prepustiti odabranom DNS servisu. Ovaj izbor kasnije se može jednostavno promijeniti kroz administratorsko sučelje.
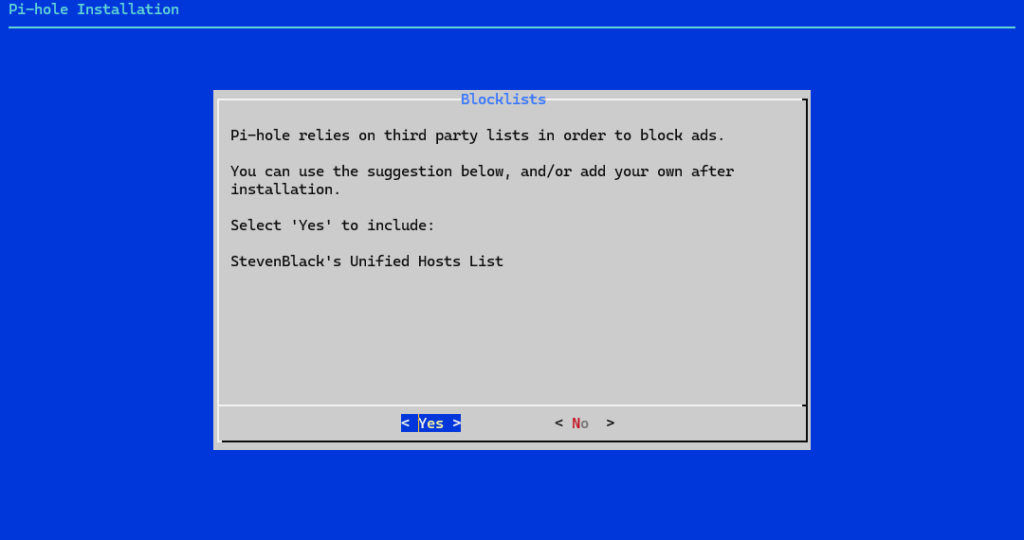
Blok liste (blocklists)
Jedan od ključnih elemenata Pi-holea® su liste domena koje se blokiraju. Tijekom instalacije automatski se dodaje osnovna, provjerena lista koja pokriva velik broj poznatih oglašivačkih i analitičkih domena.
Za početak je preporučljivo ostaviti zadanu listu, jer nudi dobar balans između učinkovitog blokiranja i minimalnog broja lažno blokiranih stranica. Dodatne liste mogu se dodavati kasnije.
Query logging
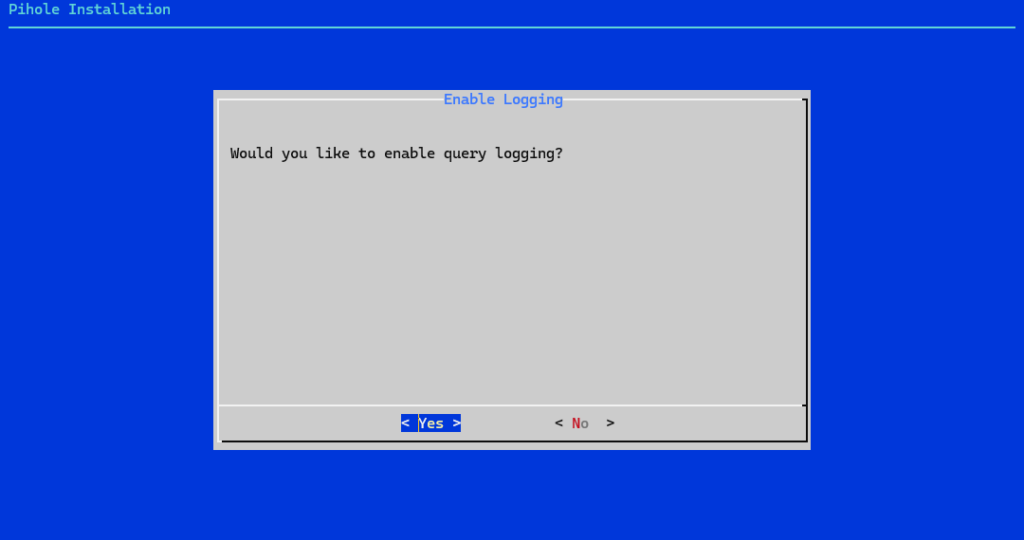
Prilikom instalacije Pi-holea jedna od opcija koja se pojavljuje je query logging. Iako može djelovati kao tehnička postavka koju je lako zanemariti, ima značajnu ulogu u načinu na koji se koristi i održava DNS sustav.
Query logging predstavlja funkcionalnost kojom Pi-hole bilježi sve DNS upite koji prolaze kroz sustav. Time se evidentira koje domene uređaji unutar mreže pokušavaju dohvatiti, kada je upit poslan, s koje IP adrese dolazi te je li određeni zahtjev blokiran ili dopušten. Na taj način omogućuje se detaljan uvid u DNS promet.
Ovakav uvid posebno je koristan u dijagnostici problema s mrežom ili pristupom određenim servisima. Također omogućuje analizu prometa, prepoznavanje neželjenih ili sumnjivih zahtjeva te dodatnu optimizaciju blocklista. U okruženjima gdje je važna kontrola nad mrežnim prometom, ova funkcionalnost predstavlja vrijedan alat.
S druge strane, potrebno je uzeti u obzir i određene nedostatke. Kontinuirano zapisivanje podataka povećava broj operacija pisanja na SD karticu, što dugoročno može utjecati na njezin vijek trajanja. Osim toga, zapisi mogu sadržavati osjetljive informacije o mrežnoj aktivnosti, što može biti relevantno s aspekta privatnosti.
Zbog toga odluka o uključivanju query logginga ovisi o prioritetima sustava. Ako je naglasak na nadzoru, analizi i jednostavnijem otklanjanju poteškoća, preporučuje se njegovo uključivanje. Ako je cilj smanjiti zapisivanje podataka i povećati razinu privatnosti, moguće ga je isključiti.
Važno je napomenuti da se ova opcija može naknadno promijeniti u bilo kojem trenutku, bez potrebe za ponovnom instalacijom Pi-holea. Time se omogućuje prilagodba sustava prema stvarnim potrebama i načinu korištenja.
Query logging nije nužan za osnovno funkcioniranje Pi-holea, ali predstavlja značajnu dodatnu funkcionalnost koja može unaprijediti upravljanje mrežnim prometom i olakšati administraciju sustava.

Web administratorsko sučelje
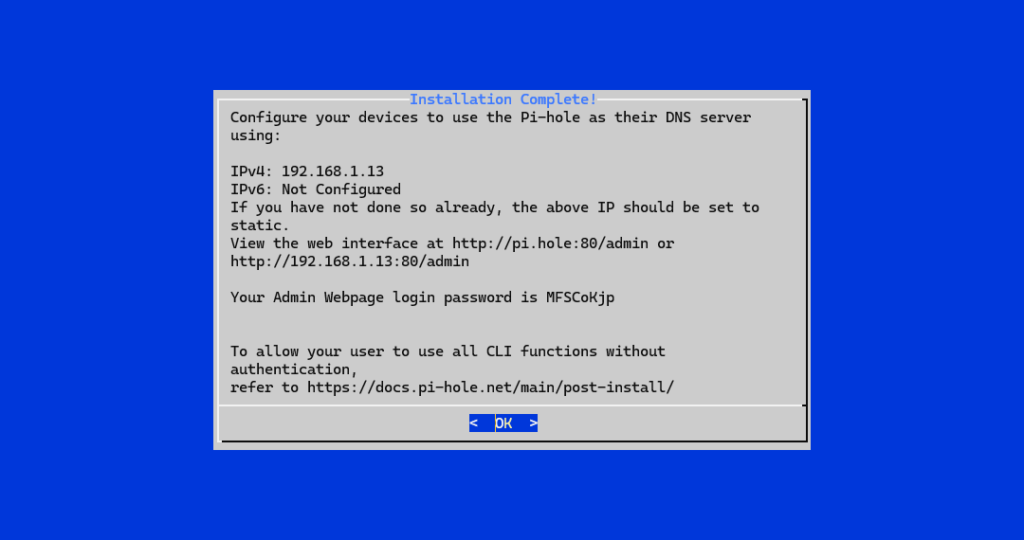
Jedna od najvećih prednosti Pi-holea® je pregledno web administratorsko sučelje. Tijekom instalacije bit će ponuđena opcija instalacije web sučelja i web poslužitelja – ovu opciju treba ostaviti uključenu.
Na kraju instalacije prikazat će se:
- URL administratorskog sučelja (npr.
http://pi.hole/admin) - inicijalna administratorska lozinka
Ovu lozinku je važno zabilježiti ili kasnije promijeniti pomoću naredbe:
pihole -a-p
DNS konfiguracija sustava
Tijekom instalacije Pi-hole® će prilagoditi DNS postavke lokalnog sustava kako bi i sam Raspberry Pi koristio Pi-hole za DNS upite. Ovo je očekivano ponašanje i ne treba ga ručno mijenjati.
Važno je napomenuti da nakon instalacije Pi-hole još uvijek ne filtrira promet cijele mreže – to će se dogoditi tek kada router ili DHCP poslužitelj bude konfiguriran da koristi Pi-hole kao primarni DNS poslužitelj, čime ćemo se baviti u sljedećem koraku projekta.
Provjera instalacije
Nakon završetka instalacije, preporučuje se provjeriti da Pi-hole servis radi:
pihole status
Također, administratorsko sučelje trebalo bi biti dostupno putem preglednika. Ako se sučelje učitava i prikazuje statistiku, osnovna instalacija je uspješno završena.
Osnovno podešavanje nakon instalacije
Nakon prve prijave u web sučelje, preporučuje se napraviti nekoliko osnovnih koraka:
- provjeriti odabrani upstream DNS
- potvrditi da su blockliste aktivne
- pregledati osnovnu statistiku
- upoznati se s prikazom DNS upita
Za početak nije potrebno ništa dodatno podešavati. Pi-hole® je dizajniran da odmah nakon instalacije nudi smislen i funkcionalan set postavki.
Što NE raditi odmah nakon instalacije
Česta pogreška je pretjerano “igranje” s postavkama odmah nakon instalacije. Ne preporučuje se:
- dodavanje velikog broja dodatnih blocklista
- agresivno blokiranje bez praćenja posljedica
- ručno mijenjanje sistemskih DNS datoteka
Najbolji pristup je pustiti Pi-hole® da nekoliko dana radi sa zadanim postavkama i promatrati ponašanje mreže.
11–16 minuta
Nakon što smo odabrali odgovarajući Raspberry Pi model za Pi-hole® projekt, sljedeći logičan korak je priprema uređaja za rad. Budući da se Raspberry Pi isporučuje bez unaprijed instaliranog operativnog sustava, prvi zadatak je instalirati Linux na microSD karticu s koje će uređaj podizati operativni sustav. Iako ovaj postupak može djelovati zastrašujuće, u praksi je vrlo jednostavan i ne zahtijeva napredno tehničko znanje.
U ovom članku proći ćemo kroz cijeli proces: od odabira operativnog sustava, odabira i pripreme microSD kartice, do prvog pokretanja Raspberry Pi-ja. Cilj je postaviti stabilnu i pouzdanu osnovu na koju ćemo u sljedećim koracima instalirati i konfigurirati Pi-hole®.
Ovaj članak dio je projekta Pi-hole®, u kojem korak po korak implementiramo rješenje za blokiranje reklama na razini cijele mreže.
Više o projektu pročitajte ovdje.
Sadržaj članka
- Što je potrebno prije instalacije
- Odabir microSD kartice
- Odabir operativnog sustava
- Umetanje microSD kartice u pomoćno računalo
- Preuzimanje Raspberry Pi Imagera
- Instalacija operativnog sustava
- Umetanje microSD kartice u Raspberry Pi Zero W
- Spajanje na Raspberry Pi putem SSH-a
- (Opcionalno) Osnovno “čišćenje” sustava
- Osnovna konfiguracija pomoću raspi-config
Sadržaj projekta
- Uvod: zašto blokirati reklame na razini cijele mreže
- Što je DNS i kako funkcionira DNS filtriranje
- Raspberry Pi kao DNS poslužitelj u kućnoj mreži
- » Instalacija operativnog sustava na Raspberry Pi
- Instalacija i osnovno podešavanje Pi-holea®
- Konfiguracija routera i/ili cloud gatewaya za Pi-hole®
- Kako testirati radi li Pi-hole ispravno
- Najčešći problem i kako ih riješiti
Što je potrebno prije instalacije
Prije nego krenemo s instalacijom, potrebno je pripremiti nekoliko osnovnih stvari:
- Raspberry Pi uređaj
- microSD kartica (preporučeno barem 8 GB, Class 10)
- zasebno pomoćno računalo (Windows, macOS ili Linux)
- čitač microSD kartica
Ako pomoćno računalo nema ugrađeni utor za microSD kartice, može se koristiti jednostavan USB čitač ili SD adapter. U praksi to znači da microSD karticu umetnemo u adapter i zatim u standardni SD utor na laptopu ili računalu.
Odabir microSD kartice

Raspberry Pi Zero W za svoj rad koristi microSD karticu kao primarni medij za pohranu operativnog sustava i podataka. Za razliku od klasičnih računala koja koriste SSD (engl. Solid State Drive) ili HDD (engl. Hard Disk Drive) diskove, Raspberry Pi Zero W se u potpunosti oslanja na SD karticu s koje se sustav podiže, na kojoj se nalazi operativni sustav i na koju se tijekom rada neprestano zapisuju i čitaju podatci. Upravo zbog toga odabir microSD kartice ima izravan utjecaj na brzinu, stabilnost i dugoročnu pouzdanost cijelog sustava.
Prilikom odabira kartice često se susrećemo s oznakama poput Class 4, Class 10, UHS-I i sličnima. Ove oznake označavaju minimalnu brzinu sekvencijalnog zapisa kartice. Class 10 jamči minimalnu brzinu zapisa od 10 MB/s, što je važno za nesmetan rad operativnog sustava. Kartice nižih klasa mogu funkcionirati, ali često uzrokuju sporije podizanje sustava, kašnjenja pri radu i u nekim slučajevima čak oštećenje operativnog sustava uslijed sporih ili nestabilnih zapisa.
Za poslužitelja poput Pi-holea®, koji je zamišljen da radi neprekidno 24/7, stabilnost zapisa na karticu važnija je od same maksimalne brzine. Operativni sustav redovito zapisuje logove, privremene datoteke i konfiguracije, a lošija kartica s vremenom može početi proizvoditi greške ili se potpuno pokvariti. Zbog toga se preporučuje koristiti kvalitetnu microSD karticu poznatog proizvođača, čak i ako je nešto skuplja, jer dugoročno smanjuje rizik od problema i gubitka podataka.
Osim klase brzine, važno je obratiti pažnju i na kapacitet kartice. Iako Raspberry Pi OS Lite i Pi-hole® zauzimaju relativno malo prostora, preporučuje se kartica od najmanje 16 GB, dok je 32 ili 64 GB razumna i praktična opcija. Veći kapacitet omogućuje dodatni prostor za logove, nadogradnje sustava i eventualne buduće servise bez potrebe za zamjenom kartice.
Za vrijeme pisanja ovog članka, u Chipoteci se mogla pronaći solidna kartica od pouzdanog proizvođača, 64 GB, Class10 za svega desetak eura, što znači da se 16GB i 32GB verzije mogu naći po još nižoj cijeni.
Odabir operativnog sustava
Raspberry Pi podržava više različitih operativnih sustava, no za Pi-hole® projekt najčešći i preporučeni izbor je Raspberry Pi OS, službena Linux distribucija optimizirana upravo za Raspberry Pi hardver. Temelji se na Debian Linuxu, stabilna je, dobro dokumentirana i ima veliku zajednicu korisnika.
Za Pi-hole® projekt nije potrebna grafička radna površina, budući da će se uređaj koristiti kao server i administrirati putem mreže. Zbog toga se preporučuje verzija:
- Raspberry Pi OS Lite (64-bit ili 32-bit)
Lite verzija dolazi bez grafičkog sučelja, zauzima manje prostora i troši manje resursa, što je idealno za svrhu DNS servera.
Umetanje microSD kartice u pomoćno računalo
Prije nego što Raspberry Pi uopće može pokrenuti operativni sustav, potrebno ga je instalirati na microSD karticu na zasebnom pomoćnom računalu. Budući da Raspberry Pi nema vlastiti mehanizam za instalaciju operativnog sustava, cijeli se postupak mora odvijati na drugom računalu, s kojeg se operativni sustav instalira na karticu.

Većina prijenosnih računala danas nema ugrađen microSD utor, već eventualno standardni SD utor. U tom slučaju koristi se SD adapter u koji se umeće microSD kartica, a zatim se adapter umeće u SD utor na računalu. Ovi SD adapteri obično stižu uz same microSD kartice. Ako ni to nije dostupno, najjednostavnije rješenje je nabaviti USB čitač kartica, koji je jeftin, univerzalan i pouzdan način povezivanja microSD kartice s računalom.
Nakon umetanja kartice, operativni sustav računala trebao bi je automatski prepoznati kao izmjenjivi medij. U Windowsima će se pojaviti kao novi disk u Exploreru, dok će se na Linuxu i macOS-u montirati kao dodatni uređaj. U ovom trenutku nije važno ako kartica ne sadrži nikakav čitljiv sadržaj ili ako operativni sustav zatraži formatiranje — to je očekivano stanje jer će se kartica ionako u potpunosti prepisati tijekom instalacije Raspberry Pi OS-a.
Važno je obratiti pozornost da je tijekom postupka instalacije odabrana ispravna kartica, osobito ako je na računalo spojeno više diskova ili vanjskih uređaja. Alati za zapisivanje operativnog sustava rade na razini cijelog uređaja, što znači da će svi postojeći podaci na odabranoj kartici biti trajno obrisani. Kratka provjera kapaciteta i naziva uređaja prije početka instalacije može spriječiti nenamjerni gubitak podataka.
Kada je microSD kartica ispravno umetnuta i prepoznata od strane sustava, spremna je za instalaciju operativnog sustava.
Preuzimanje Raspberry Pi Imagera
Raspberry Pi Imager je službeni alat namijenjen jednostavnoj i pouzdanoj instalaciji operativnih sustava na Raspberry Pi uređaje. Razvijen je od strane Raspberry Pi Foundation i prilagođen je upravo tom ekosustavu, što ga čini preporučenim izborom za većinu korisnika. Alat omogućuje automatsko preuzimanje odabranog operativnog sustava i njegovo zapisivanje na microSD karticu u nekoliko klikova. Podržan je na najčešće korištenim operativnim sustavima, uključujući Windows, macOS i Linux. Jedna od njegovih ključnih prednosti je mogućnost definiranja naprednih postavki prije same instalacije, poput postavljanja korisničkog imena, lozinke, hostname-a i mrežnih postavki. Time se uklanja potreba potreba za spajanjem monitora i tipkovnice na Raspberry Pi tijekom prvog pokretanja. Raspberry Pi Imager također automatski provjerava integritet zapisa, čime se smanjuje mogućnost grešaka pri instalaciji. Sučelje je minimalističko i prilagođeno početnicima, ali istovremeno dovoljno fleksibilno za naprednije korisnike.
Raspberry Pi Imager moguće je, i trebalo bi preuzimati isključivo sa službene web stranice kako bi se osigurala autentičnost alata i izbjegli potencijalni sigurnosni rizici povezani s neslužbenim izvorima. Dostupan je na sljedećoj službenoj web stranici:
» https://www.raspberrypi.com/software
Instalacija operativnog sustava
Sada kada imamo spremu SD karticu i Raspberry Pi Imager, vrijeme je za instalaciju operativnog sustava.
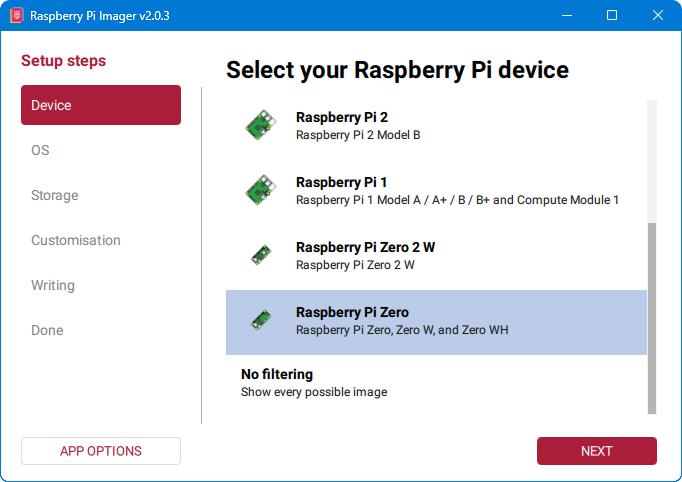
1. Odabir Raspberry Pi modela
Pokretanjem Raspberry Pi Imagera, otvara nam se sljedeći ekran. Na njemu odaberemo model Raspberry Pi uređaja. S obzirom da smo za potrebe ovog projekta uzeli Raspberry Pi Zero W, na ovom ekranu odaberemo Raspberry Pi Zero.
2. Odabir operativnog sustava
Nakon odabira Raspberry Pi modela, odabiremo operativni sustav. Prilikom odabira operativnog sustava važno je obratiti pozornost na to koji Raspberry Pi model koristimo. Općenito pravilo je da prednost uvijek ima Raspberry Pi OS Lite u 64-bitnoj verziji, ukoliko ga odabrani model podržava, jer 64-bitna verzija omogućuje bolje iskorištavanje mogućnosti procesora. Međutim, pojedini modeli, poput Raspberry Pi Zero W, ne podržavaju 64-bitnu arhitekturu procesora. U tim slučajevima potrebno je odabrati Raspberry Pi OS Lite u 32-bitnoj verziji, koja je u potpunosti dovoljna za potrebe ovog projekta.
Također je važno razlikovati dostupne varijante operativnog sustava. Raspberry Pi OS dolazi u tri osnovne verzije: Raspberry Pi OS, Raspberry Pi OS Full i Raspberry Pi OS Lite. Budući da će Raspberry Pi u ovom projektu služiti isključivo kao DNS poslužitelj, nije nam potrebna grafička radna okolina (engl. Graphical User Interface) niti dodatne desktop aplikacije. Iz tog razloga, Lite verzija predstavlja najbolji izbor, jer zauzima manje prostora, troši manje resursa i omogućuje stabilniji rad.
U slučaju da Raspberry Pi planiramo koristiti i za druge namjene koje zahtijevaju grafičko sučelje, tada ima smisla odabrati jednu od verzija s GUI-jem. Treba imati na umu da operativni sustavi s grafičkom okolinom troše više procesorskih resursa, više se zagrijavaju i imaju veću potrošnju energije, što u kontekstu stalno uključenog servera nije uvijek poželjno.
S obzirom da ovdje na listi nemamo Raspberry Pi OS Lite, odabiremo Raspberry PI OS (Other).
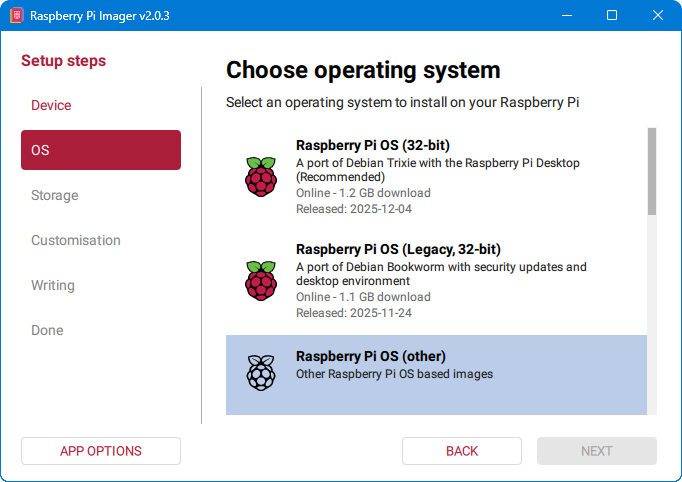
U idućem koraku koji nam se otvori, odaberemo Raspberry Pi OS Lite (32-bit).

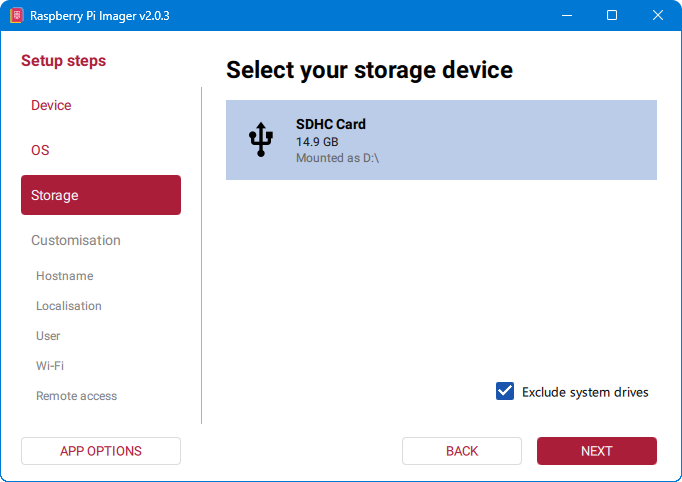
3. Odabir SD kartice
U ovom koraku važno je odabrati SD karticu koju smo spojili na pomoćno računalo. Obavezno ostaviti opciju “Exclude system drives” uključenu kako slučajno ne bi odabrali disk od pomoćnog računala pa ga u potpunosti uništili.
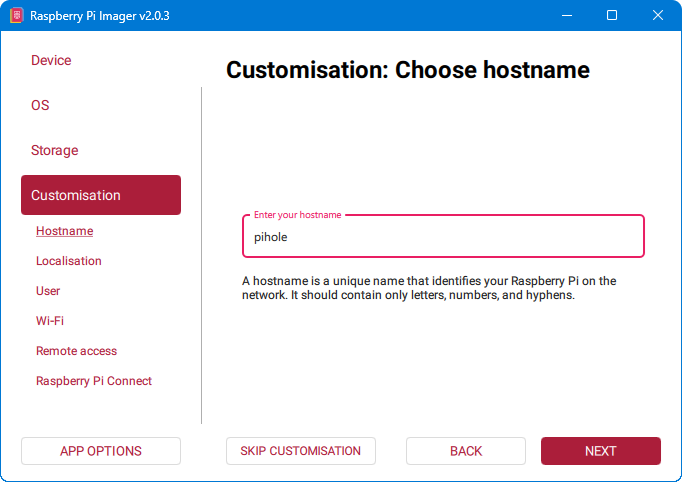
4. Unos hostnamea
Hostname je jedinstveno ime računala unutar mreže koje će vidjeti druga računala, a služi za njegovo lakše prepoznavanje i adresiranje. Umjesto pamćenja IP adrese, uređaju se može pristupiti putem tog imena, na primjer pihole, što je praktičnije i preglednije.
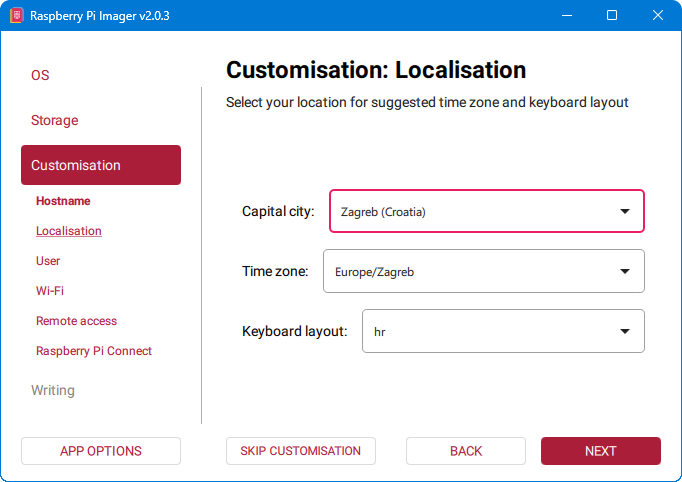
5. Odabir lokalizacije
Idući korak je odabir lokalizacije. Ovo je izuzetno bitno odabrati točno kako bi se Raspberry Pi mogao povezati na WiFi mrežu. Bez odabrane lokacije, ili sa krivom lokacijom, WiFi sučelje neće raditi.
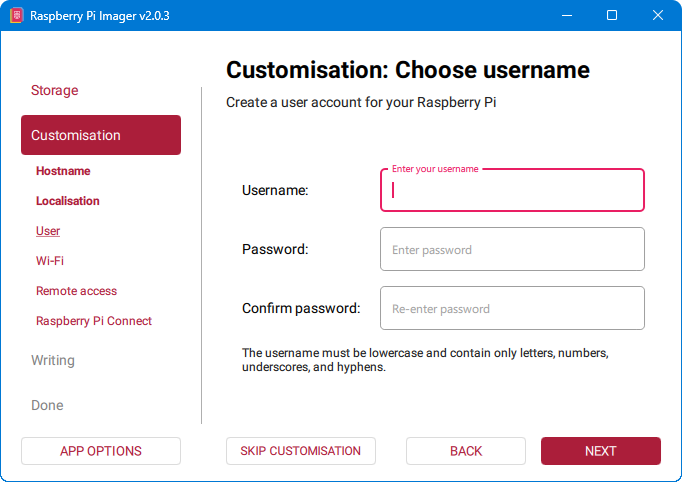
6. Unos korisnika
U ovom koraku unosimo korisničko ime i zaporku koje ćemo koristiti za spajanje na Raspberry Pi i njegovo podešavanje. Preporuka je odabrati jaču zaporku, od barem 16+ znakova, sa velikim i malim slovima, brojevima i znakovima.
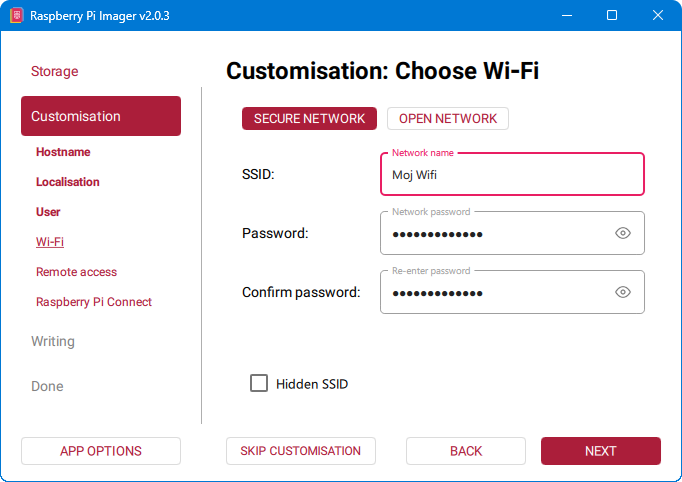
7. Unos podataka o WiFi mreži
U ovom koraku unosimo podatke o WiFi mreži na koju će se Raspberry Pi automatikom povezivati.
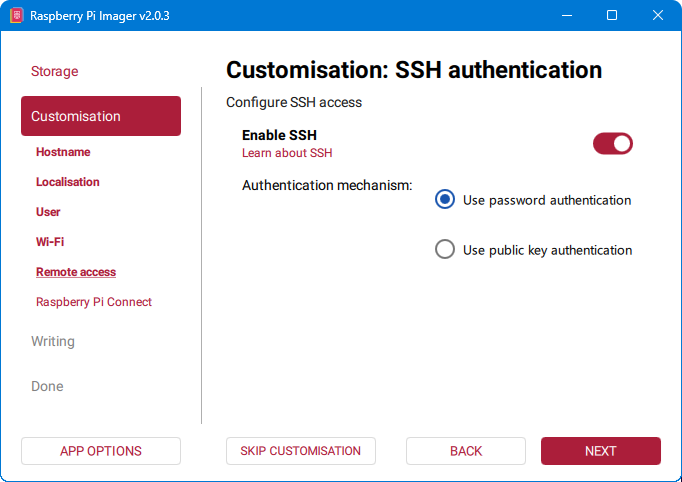
8. Odabir SSH opcije
SSH (engl. Secure Shell) je mrežni protokol koji omogućuje siguran udaljeni pristup računalu putem naredbenog retka (engl. Command Prompta). Koristi se za administraciju sustava na daljinu, pri čemu su svi podaci koji se razmjenjuju između klijenta i poslužitelja šifrirani, uključujući korisničko ime, zaporku i same naredbe.
SSH želimo uključiti kako bi se mogli spojiti na Raspberry Pi nakon instalacije, bez potrebe za spajanjem monitora, tipkovnice i miša na Raspberry Pi.
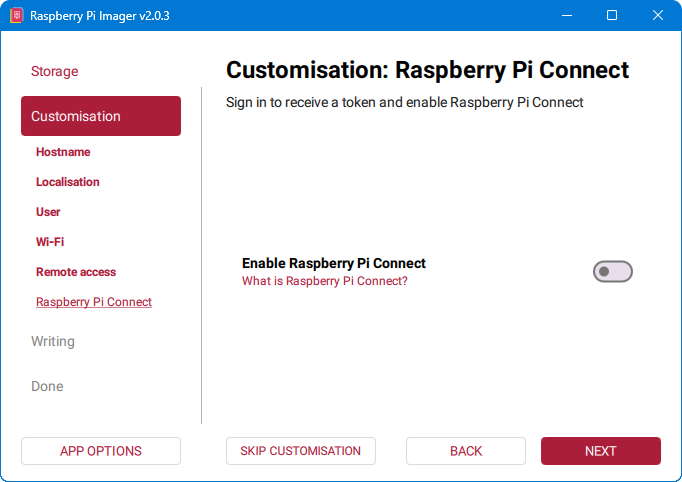
9. Odabir Raspberry Pi Connect opcije
Raspberry Pi Connect je servis koji omogućuje udaljeni pristup Raspberry Pi uređaju preko interneta putem web preglednika ili službene aplikacije, bez potrebe za izravnim SSH ili VPN pristupom. Iako može biti koristan u određenim scenarijima, u kontekstu Pi-hole® projekta i kućnog servera često se preporučuje njegovo isključivanje.
Razlog za isključivanje Raspberry Pi Connecta prvenstveno je sigurnost i minimalizam. Budući da će se Raspberry Pi koristiti kao stalno uključen mrežni servis, poželjno je smanjiti broj aktivnih servisa i izložnih točaka prema mreži ili internetu. Svaki dodatni servis predstavlja potencijalni sigurnosni rizik, čak i ako dolazi od pouzdanog proizvođača.
Osim sigurnosnog aspekta, Raspberry Pi Connect:
- koristi dodatne sistemske resurse
- uvodi ovisnost o vanjskim servisima
- nije potreban za lokalnu administraciju putem SSH-a
Za Pi-hole® je u pravilu dovoljno imati lokalni SSH pristup ili, po potrebi, pristup preko VPN-a unutar vlastite mreže. Isključivanjem Raspberry Pi Connecta sustav ostaje jednostavniji, predvidljiviji i lakši za održavanje, što je u skladu s osnovnom filozofijom pouzdanog kućnog servera.
10. Kratki prikaz svih odabranih postavki
U ovom koraku vidimo konfiguraciju koju smo postavili.

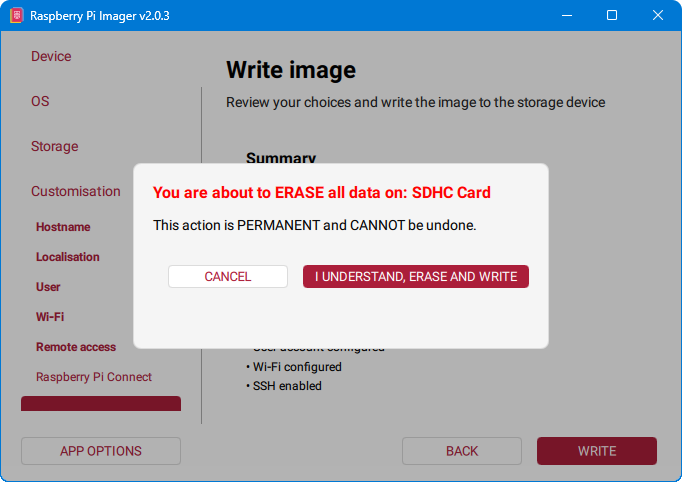
11. Potvrda instalacije
Završna potvrda instalacije. Odaberemo “I understand, erase and write”.
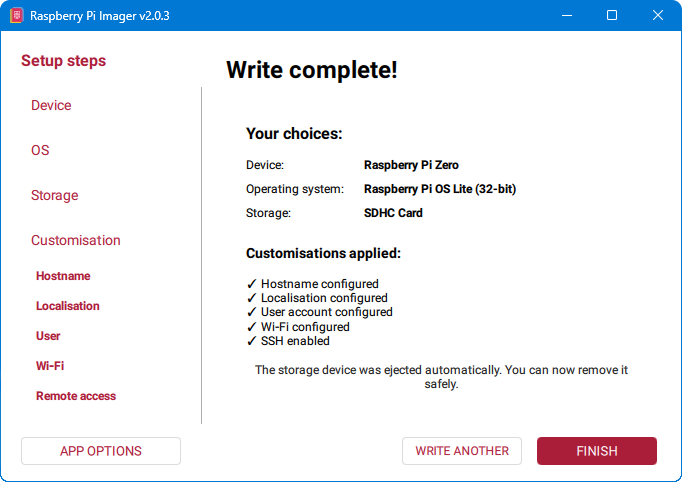
12. Završetak instalacije
Po završetku instalacije kliknemo na Finish.
Umetanje microSD kartice u Raspberry Pi Zero W

Nakon što je odgovarajuća microSD kartica odabrana i pripremljena, umetanje u Raspberry Pi je jednostavno – kartica se umeće u utor na gornjoj strani uređaja. Kartica se umeće sa kontaktima okrenutim prema dolje. Uređaj ne bi smio biti prikopčan na napajanje. Karticu treba gurnuti polagano, ali opet dovoljno snažno dok ne sjedne na dvoje mjesto.
Nakon što smo umetnuli karticu, spojimo napajanje i pričekamo dok se sustav ne digne. Ovo obično može potrajati i do 5 minuta ako se sustav podiže prvi put odmah nakon instalacije operativnog sustava.
Spajanje na Raspberry Pi putem SSH-a
Da bi se spojili na Raspberry Pi, koristimo SSH (engl. Secure Shell) koji smo omogućili u koraku 3.8.
To možemo napraviti na način da na pomoćnom računalu pokrenemo Command Prompt i u njega utipkamo sljedeće:
ssh username@hostnamePri tome nam je username korisničko ime koje smo unijeli u koraku 3.6, a hostname je ime poslužitelja koje smo unijeli u koraku 3.4. Nakon uspješnog povezivanja trebao bi nas tražiti zaporku koju smo unijeli u koraku 3.6. Tipkanjem zaporke, na samom sučelju se ne pokazuju znakovi, vizualno izgleda kao da se tipke ne primaju, ali zapravo se primaju. Nakon toga treba samo stisnuti enter. Po završetku trebali bi vidjeti nešto tipa ovoga:
Linux argon 6.12.47+rpt-rpi-v6 #1 Raspbian 1:6.12.47-1+rpt1 (2025-09-16) armv6l
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Mon Jan 5 03:22:49 2026 from 192.168.1.2
korisnik@pihole:~ $ Nakon što smo se uspješno ulogirali u Raspberry Pi, prvo ga idemo ažurirati na najnoviju verziju. Utipkavamo i okidamo sljedeće naredbe:
sudo apt full-upgrade -y
sudo rebootŠto zapravo znače te naredbe?
sudo – sudo znači “superuser do” i omogućuje izvršavanje naredbe s administratorskim (root) ovlastima. Budući da se ažuriraju sistemski paketi, ova razina ovlasti je nužna.
apt – apt je alat za upravljanje paketima na Debian i Debian-based sustavima (uključujući Raspberry Pi OS). Koristi se za instalaciju, ažuriranje i uklanjanje softvera.
full-upgrade – full-upgrade nadograđuje sve instalirane pakete na njihove najnovije dostupne verzije i pritom smije ukloniti ili zamijeniti postojeće pakete ako je to potrebno za ispravno rješavanje ovisnosti.
-y – opcija -y automatski odgovara s “yes” na sva pitanja tijekom procesa nadogradnje. Time se omogućuje da se naredba izvrši bez dodatne interakcije. Bez -y, sustav bi tijekom nadogradnje tražio ručnu potvrdu.
(Opcionalno) Osnovno “čišćenje” sustava
Za server koji će raditi 24/7 korisno je ukloniti nepotrebne pakete:
sudo apt autoremove -yOvo nije obavezno, ali pomaže dugoročnoj urednosti sustava.
Osnovna konfiguracija pomoću raspi-config
Raspberry Pi dolazi s alatom raspi-config koji omogućuje jednostavno podešavanje ključnih postavki sustava. Konfiguracija se može pokrenuti sljedećom naredbom:
sudo raspi-configUtipkavanjem navedene naredbe, dobijemo sljedeći ekran:
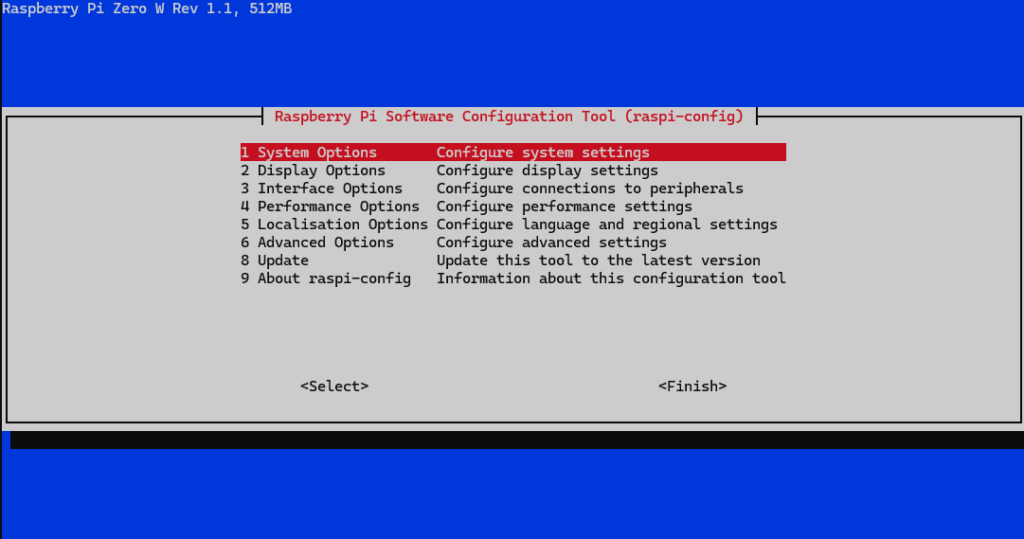
Jednom kada smo u tome ekranu, navigirati možemo putem strelica na tipkovnici.
Prva stvar koju ćemo napraviti je onemogućavanje nepotrebnih sučelja koja uopće nećemo koristiti za potrebe DNS poslužitelja. Prvo ćemo otvoriti opciju 3 Interface Options nakon čega dobijemo sljedeći ekran.
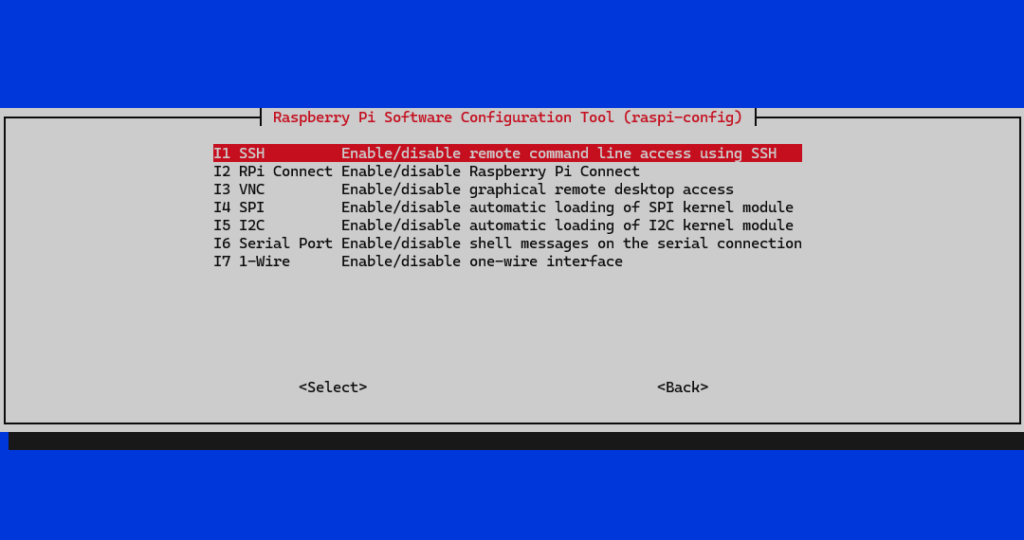
Budući da Raspberry Pi u ovom projektu služi isključivo kao mrežni poslužitelj, sva nepotrebna hardverska sučelja i grafičke usluge mogu se isključiti kako bi se smanjila potrošnja resursa i povećala sigurnost sustava. Ostaviti ćemo uključen samo SSH pristup.
U idućem koraku ćemo isključiti Wi-Fi power saving. Ova opcija povremeno gasi WiFi sučelje nakon nekog vremena neaktivnosti kako bi uštedila energiju, međutim to nam nije poželjno jer će nam usporiti rad DNS poslužitelja, a potrošnja energije je skoro zanemariva.
Otvorit ćemo opciju 6 Advanced Options.
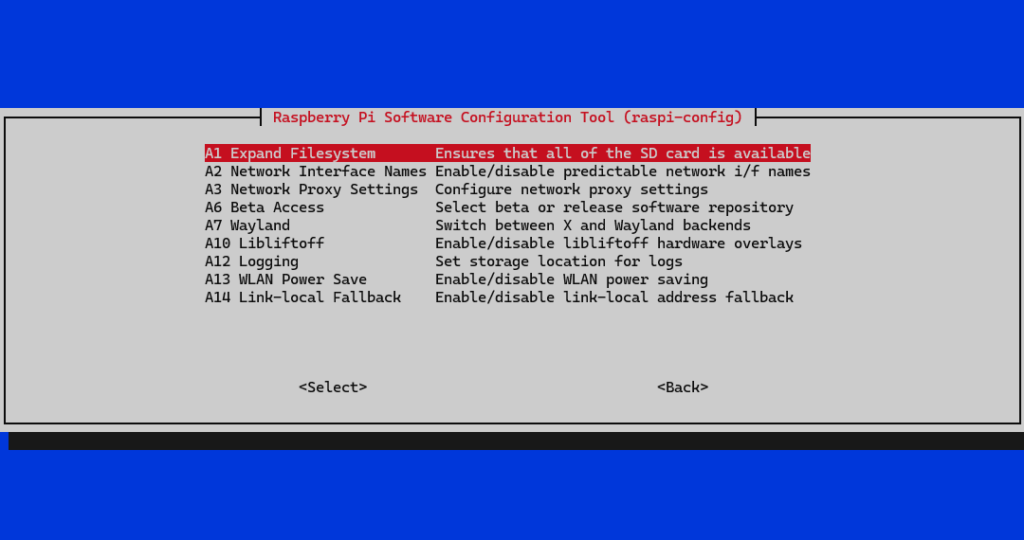
Na opciji A13 možemo isključiti WLAN power saving.
S ovime smo završili osnovnu konfiguraciju Raspberry Pi Zero W uređaja. Idući korak je instalacija softvera za blokiranje reklama, Pi-hole®.
6–9 minuta
Raspberry Pi je malo računalo (engl. single-board computer) veličine kreditne kartice, dizajnirano s ciljem da bude pristupačno, energetski učinkovito i dovoljno fleksibilno za učenje, eksperimentiranje i razne praktične projekte. Iako je fizički malen, Raspberry Pi je punokrvno računalo koje pokreće Linux, ima mrežne mogućnosti i sposoban je neprekidno raditi 24/7.
Projekt je nastao pod okriljem Raspberry Pi Foundation, s idejom da se omogući širok pristup računalstvu i programiranju. S vremenom se Raspberry Pi proširio daleko izvan obrazovnih okvira te je postao vrlo popularna platforma u svijetu kućnih servera, automatizacije i homelab projekata.
Ovaj članak dio je projekta Pi-hole®, u kojem korak po korak implementiramo rješenje za blokiranje reklama na razini cijele mreže.
Više o projektu pročitajte ovdje.
Sadržaj članka
Sadržaj projekta
- Uvod: zašto blokirati reklame na razini cijele mreže
- Što je DNS i kako funkcionira DNS filtriranje
- » Raspberry Pi kao DNS poslužitelj u kućnoj mreži
- Instalacija operativnog sustava na Raspberry Pi
- Instalacija i osnovno podešavanje Pi-holea®
- Konfiguracija routera i/ili cloud gatewaya za Pi-hole®
- Kako testirati radi li Pi-hole ispravno
- Najčešći problem i kako ih riješiti
O Raspberry Pi računalima
Jedan od najčešćih razloga zašto se Raspberry Pi koristi u ovakvim projektima jest njegova cijena. Za razliku od klasičnih računala, Raspberry Pi ne sadrži skupe komponente poput snažnih procesora, velikih količina radne memorije ili zasebnih grafičkih kartica. Umjesto toga, koristi ARM arhitekturu optimiziranu za nisku potrošnju energije i stabilan rad.
Uz to, Raspberry Pi se proizvodi u vrlo velikim količinama, bez nepotrebnih dodataka poput kućišta, monitora ili pohrane, što dodatno snižava cijenu. Rezultat je uređaj koji troši svega nekoliko vata, ne zagrijava se značajno i može biti stalno uključen bez primjetnog utjecaja na račun za električnu energiju. Upravo ta kombinacija niske cijene i male potrošnje čini ga idealnim kandidatom za stalno uključene servise poput Pi-holea®.
Raspberry Pi kao DNS poslužitelj
Pi-hole® je DNS poslužitelj s dodatnom logikom za filtriranje domena povezanih s oglašavanjem i praćenjem. Takav zadatak ne zahtijeva snažan procesor niti velike količine memorije, već stabilnu mrežnu povezanost i pouzdan rad.
Raspberry Pi se u tom kontekstu pokazuje kao gotovo idealna platforma:
- dovoljno je snažan za obradu DNS upita
- radi tiho i bez pokretnih dijelova
- zauzima vrlo malo prostora
- može raditi neprekidno 24/7
- jednostavno se održava i nadograđuje
Za većinu kućnih mreža, čak i najjeftiniji modeli Raspberry Pi-a mogu bez problema opsluživati desetke uređaja istovremeno.
Pregled Raspberry Pi modela
Tijekom godina pojavilo se više generacija i varijanti Raspberry Pi računala. Iako svi dijele istu osnovnu filozofiju, razlikuju se po snazi, količini memorije i mrežnim mogućnostima. U nastavku će biti spomenuto nekoliko najčešćih modela koji se mogu naći na tržištu.
Raspberry Pi Zero i Zero W

Raspberry Pi Zero je najmanji i najjeftiniji model u Raspberry Pi obitelji, a pritom zadržava sve osnovne funkcionalnosti potrebne za jednostavne mrežne i serverske zadatke. Njegove hardverske specifikacije su skromne u usporedbi s većim modelima, no upravo ta jednostavnost donosi ključne prednosti u vidu vrlo niske potrošnje energije i minimalnog zagrijavanja. Zbog svoje izuzetno male fizičke veličine, Raspberry Pi Zero može se smjestiti gotovo bilo gdje, što ga čini idealnim za projekte gdje prostor igra važnu ulogu. Model Raspberry Pi Zero W dodatno uključuje ugrađene Wi-Fi i Bluetooth module, čime se uklanja potreba za dodatnim adapterima i pojednostavljuje mrežno povezivanje. Upravo zbog te kombinacije niske cijene, male potrošnje i osnovne mrežne funkcionalnosti, Raspberry Pi Zero W često je prvi izbor za jednostavne, namjenske servise koji trebaju raditi neprekidno u pozadini.
Za vrijeme pisanja ovog članka, Raspberry Pi Zero W model je dostupan u Chipoteci za nešto malo više od 20,00 €.
Model dolazi sa 802.11n WiFi modulom koji radi na 2.4 GHz te dostiže prosječnu brzinu od 30 Mbit/s. Ima 512MB radne memorije i 1 GHz jednojezgreni procesor koji ne zahtjeva aktivno ni pasivno hlađenje.
Prednosti:
- vrlo niska cijena
- izuzetno mala potrošnja energije
- vrlo kompaktan
- minimalno zagrijavanje
- ne zahtjeva hlađenje
Nedostaci:
- slabiji procesor
- ograničena memorija
- nedostatak ethernet porta
Raspberry Pi 3 (Model B / B+)

Raspberry Pi 3 često se smatra best-buy modelom jer nudi vrlo dobar omjer cijene, potrošnje energije i stvarnih performansi. Njegove hardverske specifikacije više su nego dovoljne za većinu kućnih i manjih homelab projekata. Za razliku od Zero modela, ima ethernet port, koji omogućuje pouzdanu žičnu mrežnu povezanost, dok integrirani Wi-Fi i Bluetooth moduli pružaju dodatnu fleksibilnost, osobito u situacijama gdje žična mreža nije dostupna.
Zbog snažnijeg procesora i veće potrošnje energije, Raspberry Pi 3 proizvodi više topline nego Zero modeli. Iako pasivno hlađenje u većini slučajeva nije nužno, ipak se preporučuje, osobito kod neprekidnog rada ili smještaja u zatvoreno kućište. Bez adekvatnog hlađenja može doći do termalnog ograničavanja performansi.
Za vrijeme pisanja ovog članka, Raspberry Pi 3 Model B+ je dostupan u Chipoteci za 60,00 €.
Model dolazi sa ethernet portom brzine 100 Mbit/s, kao i 802.11n WiFi modulom koji radi na 2.4 i 5 GHz te dostiže prosječnu brzinu od 60 Mbit/s. Ima 1GB radne memorije i 1.2 GHz četverojezgreni procesor koji zahtjeva barem pasivno hlađenje.
Prednosti:
- niska cijena
- mala potrošnja energije
- ethernet port
- umjereno zagrijavanje
- zahtjeva pasivno hlađenje
Nedostaci:
- ograničena memorija
- ograničena brzina ethernet porta
- većih dimenzija
Raspberry Pi 4 i 5

Raspberry Pi 4 i 5 su napravili veliki iskorak u odnosu na prethodne generacije i po performansama se već približavaju klasičnim stolnim računalima. Dostupni su u više varijanti s različitim količinama radne memorije (2 GB, 4 GB i 8 GB RAM-a), što ih čini vrlo fleksibilnim za razne namjene – od jednostavnih mrežnih servisa do zahtjevnijih homelab projekata.
Za vrijeme pisanja ovog članka, Raspberry Pi 5, model s 8GB RAM-a je dostupan u Chipoteci za 120,00 €.
Zbog snažnijeg procesora i veće potrošnje energije, Raspberry Pi 5 proizvodi više topline nego stariji modeli. Iako aktivno hlađenje u većini slučajeva nije nužno, pasivno hlađenje se snažno preporučuje, osobito kod neprekidnog rada ili smještaja u zatvoreno kućište. Bez adekvatnog hlađenja može doći do termalnog ograničavanja performansi.
Model dolazi sa gigabitnim ethernet portom, 802.11ac WiFi modulom koji radi na 2.4 i 5 GHz te dostiže prosječnu brzinu od 60 Mbit/s. Ima 8GB radne memorije i 2.4 GHz četverojezgreni procesor koji zahtjeva barem pasivno hlađenje.
Prednosti:
- velike performanse
- niska cijena
- ethernet port
- različite RAM konfiguracije
Nedostaci:
- visoka cijena
- veća potrošnja energije
- većih dimenzija
- veće zagrijavanje
- zahtjeva aktivno hlađenje
Odabir Raspberry Pi modela za Pi-hole® projekt
Odabir odgovarajućeg Raspberry Pi modela za Pi-hole® projekt ovisi prvenstveno o veličini mreže, broju uređaja koji će koristiti DNS te o tome planira li se na istom uređaju pokretati još neki dodatni servisi. Budući da Pi-hole® ima vrlo skromne hardverske zahtjeve, u većini slučajeva nije potrebno posezati za najsnažnijim modelima.
Općenite preporuke mogu se svesti na sljedeće smjernice:
- Mala kućna mreža (do 15 uređaja): Raspberry Pi Zero W
Idealan izbor za jednostavne postavke u manjim kućanstvima. Nudi dovoljno snage za stabilno DNS filtriranje uz minimalnu potrošnju energije i vrlo nisku cijenu. Posebno je pogodan ako Pi-hole® ima isključivo jednu namjenu. - Prosječna ili veća kućna mreža: Raspberry Pi 3 i 4
Uravnotežen i provjereni modeli koji bez problema podnose velik broj istovremenih DNS upita. Dobar je izbor za kućanstva s više računala, pametnih telefona, televizora i drugih mrežnih uređaja koji rade istovremeno, uz zadržavanje jednostavnosti i pouzdanosti. - Dodatni servisi uz DNS poslužitelj: Raspberry Pi 4 i 5 (4 GB RAM-a ili više)
Ako se uz Pi-hole® planira pokretanje dodatnih servisa, poput VPN-a, alata za nadzor mreže ili kućne automatizacije, ovi modeli su idealni jer imaju mogućnost odabira veće količine radne memorije koja osigurava dugoročnu stabilnost i fleksibilnost sustava.
Važno je naglasiti da Pi-hole® sam po sebi ima vrlo male hardverske zahtjeve. Upravo zato je u većini slučajeva pametnije odabrati slabiji, energetski učinkovitiji model koji će pouzdano obavljati svoju zadaću, nego ulagati u snažniji hardver čije se mogućnosti neće u potpunosti iskoristiti.
Raspberry Pi je iznimno fleksibilna i pristupačna platforma koja se savršeno uklapa u projekte poput Pi-holea®. Njegova niska potrošnja energije, povoljna cijena i stabilan rad čine ga idealnim kandidatom za stalno uključen lokalni DNS poslužitelj. Bez obzira radi li se o maloj kućnoj mreži ili složenijem homelab okruženju, postoji Raspberry Pi model koji može zadovoljiti potrebe bez nepotrebnog troška i dodatne složenosti.
Za potrebe ovog projekta odabran je Raspberry Pi Zero W. U sljedećem koraku projekta pozabavit ćemo se instalacijom operativnog sustava na Raspberry Pi Zero W i pripremom uređaja za pokretanje Pi-holea®. Neovisno o odabranom modelu, idući korak je sličan s obzirom da svi modeli koriste isti operativni sustav.
6–9 minuta
U svakodnevnom korištenju interneta rijetko razmišljamo o tome što se zapravo događa u pozadini kada u web preglednik upišemo adresu neke web stranice. Nekoliko slova u adresnoj traci dovoljno je da se u djeliću sekunde učita sadržaj s poslužitelja (engl. Server) koji se često nalazi na drugom kraju svijeta. Iako taj proces djeluje jednostavno, iza njega stoji niz koraka i sustava koji omogućuju da računala međusobno komuniciraju na pouzdan i predvidljiv način.
Jedan od ključnih elemenata te komunikacije je DNS (engl. Domain Name System). DNS je sustav koji internetske domene, koje su ljudima razumljive i pamtljive, prevodi u IP adrese koje računala koriste za međusobnu komunikaciju. Bez DNS-a, korištenje interneta kakvog danas poznajemo bilo bi nepraktično i znatno složenije, jer bismo za svaku web stranicu morali pamtiti i ručno unositi njezinu numeričku adresu.
U kontekstu sigurnosti, privatnosti i blokiranja neželjenog sadržaja, DNS ima još jednu vrlo važnu ulogu. Budući da svaki zahtjev prema nekoj internetskoj domeni prolazi upravo kroz DNS, taj se mehanizam može iskoristiti i za filtriranje prometa. Upravo na tom principu temelji se DNS filtriranje, tehnika koja omogućuje kontrolu nad time koje će se domene moći dohvatiti, a koje će biti blokirane već u samom začetku komunikacije. U nastavku će biti objašnjeno na vrlo laičkoj razini kako DNS funkcionira i na koji način DNS filtriranje čini temelj rješenja poput Pi-holea®.
Ovaj članak dio je projekta Pi-hole®, u kojem korak po korak implementiramo rješenje za blokiranje reklama na razini cijele mreže.
Više o projektu pročitajte ovdje.
Sadržaj članka
Sadržaj projekta
- Uvod: zašto blokirati reklame na razini cijele mreže
- » Što je DNS i kako funkcionira DNS filtriranje
- Raspberry Pi kao DNS poslužitelj u kućnoj mreži
- Instalacija operativnog sustava na Raspberry Pi
- Instalacija i osnovno podešavanje Pi-holea®
- Konfiguracija routera i/ili cloud gatewaya za Pi-hole®
- Kako testirati radi li Pi-hole ispravno
- Najčešći problem i kako ih riješiti
Kako računala komuniciraju: Analogija s klasičnom poštom
Kako bismo razumjeli što su DNS i DNS filtriranje, potrebno je najprije shvatiti kako računala međusobno komuniciraju preko interneta. Ukratko, da bi komunikacija bila moguća, svako računalo mora se nekako identificirati. Najlakše je to objasniti analogijom s klasičnom poštom. Kada šaljemo pismo, na omotnici se uvijek nalaze dvije adrese: adresa pošiljatelja i adresa primatelja. One sadrže ime i prezime, ulicu, kućni broj, poštanski broj, grad i državu. Zahvaljujući tim podacima, poštar zna kome treba dostaviti pismo, ali i kome ga vratiti ako isporuka nije moguća.
IP adresa – identitet računala na mreži
Računala funkcioniraju na vrlo sličan način. Svaki uređaj na mreži ima svoju jedinstvenu adresu, a u svakom zahtjevu koji šalje preko interneta navodi se izvorišna adresa (tko šalje zahtjev) i odredišna adresa (kome se zahtjev šalje). Razlika između poštanske i računalne adrese je samo u načinu zapisivanja. Računala koriste IP adresu (engl. Internet Protocol address). Iako naziv zvuči kompliciran, IP adresa nije ništa više nego samo numerička oznaka, odnosno niz brojeva odvojenih točkama. Postoji više različitih verzija IP adresa od kojih neke imaju više brojeva i koriste i slova, za a potrebe ovog primjera uzmimo najjednostavniju i najčešće korištenu verziju, IPv4, koja se sastoji od četiri broja razdvojena točkama, na primjer: 192.100.25.128.
Primjer komunikacije između računala i poslužitelja
Zamislimo sada tipičan primjer komunikacije. Jedno računalo je poslužitelj na kojem se nalazi web stranica, a drugo je naše kućno računalo. Kada želimo otvoriti tu stranicu, teoretski bismo u web preglednik mogli upisati IP adresu poslužitelja. Naše računalo tada šalje zahtjev poslužitelju u kojem navodi IP adresu primatelja (poslužitelja) i vlastitu IP adresu kao pošiljatelja, uz dodatne tehničke informacije poput protokola i porta koji trenutno nisu relevantni za primjer. Poslužitelj primi zahtjev, vidi tko ga je poslao i odgovara tako da u odgovor stavlja sadržaj web stranice, ali sada s obrnutim ulogama: IP adresa poslužitelja je pošiljatelj, a IP adresa našeg računala primatelj. Naše računalo primi podatke i prikaže stranicu u web pregledniku.
Internetske domene – imena umjesto brojeva
Sve to zvuči jednostavno i logično, ali postavlja se jedno pitanje: kada smo zadnji put u preglednik ručno upisali IP adresu neke web stranice? Vrlo vjerojatno, nikada. U analogiji s razmjenom pošte između dvije kućne adrese, zanimljivo je primijetiti da kućne adrese nisu definirane nizovima nasumičnih brojeva, iako bi to strojevima u poštanskim sortirnicama bilo daleko jednostavnije za obradu. Umjesto toga, ulice i trgovi nose imena kulturnih, povijesnih ili sportskih ličnosti upravo zato što su takve adrese ljudima lakše pamtljive i smislenije. Sličan problem postoji i u računalnim mrežama. IP adrese su generički numerički nizovi brojeva i/ili slova koje računala savršeno razumiju, ali su ljudima teške za čitanje i gotovo nemoguće za pamćenje. Zbog toga je razvijen sustav internetskih domena, tekstualnih imena koja upisujemo u internetske preglednike, poput google.hr ili dsofic.dev, koja su ljudima lakša za pamćenje, a koja računala ih znaju u pozadini automatski prevesti u IP adrese na temelju kojih dalje komuniciraju.
DNS poslužitelj – prevoditelj domena u IP adrese
Kako bi ta pretvorba iz domene u IP adresu uopće bila moguća, u komunikaciju se uključuje treće računalo, odnosno dodatni poslužitelj koji se naziva DNS poslužitelj (engl. Domain Name System Server). Taj poslužitelj ne sudjeluje izravno u razmjeni sadržaja, već služi kao pomoćni posrednik između dva računala koja žele komunicirati. Kada u web preglednik upišemo neku adresu, primjerice dsofic.dev, naše računalo najprije kontaktira DNS poslužitelj i postavlja vrlo jednostavno pitanje: kojoj IP adresi pripada ova internetska domena? Tek nakon što dobije odgovor, računalo zna kojem poslužitelju treba poslati stvarni zahtjev, odnosno u zahtjevu postavlja ispravnu IP adresu primatelja. Gdje se DNS poslužitelji zapravo nalaze i tko ih održava? U većini slučajeva DNS poslužitelje automatski osigurava internet provider (engl. Internet Service Provider, skr. ISP), poput A1-a, HT-a ili Telemacha. Osim njih, postoje i javni DNS servisi koje održavaju velike tehnološke tvrtke, poput Cloudflare DNS i Google Public DNS, a koje korisnici često koriste zbog brzine, pouzdanosti ili privatnosti.
Vratimo se sada korak unazad na primjer dohvata web stranice. Rekli smo da naše računalo šalje zahtjev prema poslužitelju i kao odgovor dobiva sadržaj web stranice. To je najjednostavniji mogući primjer komunikacije, no u stvarnosti je situacija nešto složenija. Kada se web stranica učita, priča tu ne završava. Sama stranica često sadrži dodatne poveznice i elemente koji upućuju na druge internetske domene, s kojih se naknadno dohvaća sadržaj. To mogu biti slike, skripte, analitički alati, ali vrlo često i reklame. Drugim riječima, mi smo dohvatili osnovnu web stranicu s jednog poslužitelja, ali ona našem računalu dalje govori: “Osim mene, dohvati još i sadržaj s ove internetske domene, i s ove, i s ove.” Među tim dodatnim internetskim domenama često se nalaze upravo domene povezane s oglašavanjem. Naše računalo tada za svaku od tih internetskih domena radi novi zahtjev. Prvo ponovno kontaktira DNS poslužitelja i pita: kojoj IP adresi odgovara ova internetska domena? Nakon što dobije odgovor, ponavlja cijeli postupak komunikacije, potpuno isto kao i kod izvornog dohvata web stranice.
DNS filtriranje kao rješenje problema
U tom trenutku počinje se nazirati rješenje našeg problema. Kada bismo mogli preuzeti ulogu DNS poslužitelja i reći: “Ako web stranica traži učitavanje sadržaja s internetske domene za koju znam da je povezana s reklamama, nemoj uopće dohvaćati taj sadržaj”, mogli bismo učinkovito filtrirati ono što želimo, a što ne želimo učitati. I upravo to možemo napraviti tako da u svojoj lokalnoj mreži podignemo vlastiti lokalni DNS poslužitelj koji će imati tu kontrolu nad DNS upitima, a za tu svrhu možemo koristiti Pi-hole®, alat koji preuzima ulogu DNS poslužitelja i omogućuje filtriranje sadržaja već na razini samog upita, prije nego što reklame uopće dođu do uređaja.
Pi-hole® se postavlja kao DNS poslužitelj za cijelu mrežu. Kada neki uređaj pokuša dohvatiti domenu povezanu s reklamama ili praćenjem, Pi-hole® taj zahtjev prepoznaje i jednostavno ga blokira – odgovor nikad ne stigne do uređaja, a reklama se uopće ne učita. Budući da se sve događa na DNS razini, ovo vrijedi za sve aplikacije i sve uređaje spojene na lokalnu mrežu, ne samo za web preglednike.
Na prvu se može činiti da je pokretanje vlastitog servera skup i kompliciran pothvat. I doista, za snažne servere potreban je ozbiljan softver i hardver koji obično rezultira i povećom potrošnjom energije što zahtjeva poveći novčanik. Međutim, za lokalni DNS server za filtriranje to uopće nije slučaj. Pi-hole® je besplatni open-source projekt, a za njegovo pokretanje dovoljan je mali, jeftin i energetski učinkovit uređaj poput Raspberry Pi računala, koji može raditi neprekidno uz zanemarivu potrošnju struje.
U sljedećem dijelu pozabaviti ćemo se Raspberry Pi računalom, zašto je posebno pogodno za ovakav zadatak, te koji model u moru modela odabrati za svrhu ovog projekta.
3–5 minuta
Reklame su postale pošast modernog interneta. Danas je gotovo nemoguće otvoriti i najobičniji novinski članak, a da isti ne sadrži neki oblik reklama. Nerijetko se dogodi da web stranice imaju više reklama nego samog sadržaja. Osim što narušavaju iskustvo čitanja, iza njih se često ne kriju samo oglasi za proizvode i usluge, već narušavaju privatnost agresivnim praćenjem posjetilaca, stvaraju nepotreban mrežni promet i uvode brojne sigurnosne rizike.
Blokiranjem reklama ne dobivamo samo vizualno čišće stranice, već i brzinu, manji mrežni promet, te veću privatnost za sve uređaje na mreži.
U ovom projektu proći ćemo kroz korake izgradnje vlastitog rješenja na lokalnoj mreži koje će nam pomoći u borbi protiv ove pošasti. Umjesto instaliranja dodatnog softvera na svaki uređaj zasebno, podići ćemo centralizirani sustav za blokiranje reklama na svim uređajima u lokalnoj mreži (računalima, pametnim telefonima, tabletima, pametnim televizorima) itd.
Ovaj projekt namijenjen je korisnicima koji žele više kontrole nad vlastitom mrežom, ali ne žele složena i skupa rješenja. Osnovno razumijevanje rada računala i mreža bit će korisno, ali nije preduvjet, jer će svi ključni pojmovi i koncepti biti postupno objašnjeni kroz sam projekt.
Ovaj članak dio je projekta Pi-hole®, u kojem korak po korak implementiramo rješenje za blokiranje reklama na razini cijele mreže.
Više o projektu pročitajte ovdje.
Sadržaj članka
Sadržaj projekta
- » Uvod: zašto blokirati reklame na razini cijele mreže
- Što je DNS i kako funkcionira DNS filtriranje
- Raspberry Pi kao DNS poslužitelj u kućnoj mreži
- Instalacija operativnog sustava na Raspberry Pi
- Instalacija i osnovno podešavanje Pi-holea®
- Konfiguracija routera i/ili cloud gatewaya za Pi-hole®
- Kako testirati radi li Pi-hole ispravno
- Najčešći problem i kako ih riješiti
Blokiranje reklama
Postoji više načina blokiranja reklama, a razlikuju se po učinkovitosti, složenosti postavljanja i količini održavanja koje zahtijevaju. U praksi se najčešće susrećemo s dva temeljno različita pristupa blokiranju reklama, koji se razlikuju po mjestu na kojem se blokiranje odvija.
Blokiranje reklama na web preglednicima

Najćešći, najbrži i najjednostavniji način blokirana reklama je na razini web preglednika (engl. web browser), pomoću proširenja (engl. extensions) koja filtriraju sam sadržaj web stranica, tzv. ad-blockeri. Za prosječnu osobu, ovakav način blokiranja reklama može biti vrlo učinkovit na jednom uređaju, a uz to zahtjeva minimalno truda i tehničkog predznanja.
Međutim, ovaj pristup ima nekoliko ozbiljnih nedostataka. Kao što je spomenuto, on može dobro funkcionirati na jednom uređaju, međutim u praksi, u kućanstvima obično imamo nekoliko uređaja, s čime postaje vrlo nepraktičan: svaki preglednik zahtijeva zasebnu instalaciju ad-blockera što znači da svaki uređaj zahtijeva zasebno inicijalno podešavanje i održavanje.
Dodatni problem predstavlja činjenica da sami dodaci dolaze od neprovjerenih trećih strana i time predstavljaju dodatni sigurnosni rizik jer ne znamo što se zapravo može kriti u njima, prate li nas, prodaju naše informacije četvrtim stranama i sl.
Situaciju dodatno komplicira činjenica da sve više preglednika ograničava ili u potpunosti onemogućava klasične ad-blockere, a na nekim uređajima poput pametnih telefona, pametnih televizora, IoT uređaja njihova instalacija uopće nije moguća jer preglednici ne podržavaju proširenja.
Blokiranje reklama na razini mreže
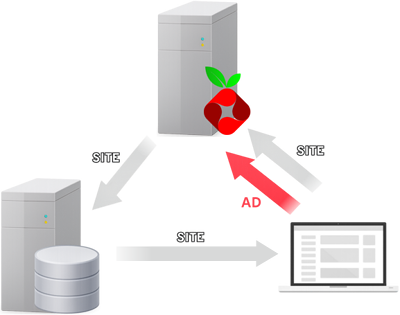
Ako promotrimo kućnu ili uredsku mrežu kao cjelinu, postaje jasno da se svi uređaji susreću s istim problemom. Svaki od njih šalje zahtjeve prema istim oglašivačkim i analitičkim servisima. Bez obzira radi li se o računalu, pametnom telefonu, tabletu ili pametnom televizoru, svi oni u pozadini obavljaju vrlo sličnu mrežnu komunikaciju. Zato se prirodno nameće pitanje: zašto bismo taj problem rješavali na svakom uređaju zasebno, kada ga možemo riješiti na jednom, centralnom mjestu?
Za razliku od blokiranja na razini aplikacije ili preglednika, mrežno blokiranje djeluje prije nego što se uspostavi stvarna komunikacija. Time se reklame i servisi za praćenje uklanjaju u samom začetku, bez da uređaji uopće znaju da su pokušali dohvatiti takav sadržaj. U tom scenariju uređaji više nemaju potrebu znati što je reklama, a što nije, oni jednostavno nikada ne dobiju priliku komunicirati s domenama koje služe za oglašavanje i praćenje.
Ovakav pristup ima nekoliko ključnih prednosti:
- ne ovisi o vrsti uređaja ili operativnom sustavu
- ne zahtijeva instalaciju dodatnog softvera na klijentskoj strani
- djeluje jednako na sve aplikacije, ne samo na web preglednike
- pruža centralizirani uvid i kontrolu nad mrežnim prometom
Upravo ovdje počinje priča o Pi-holeu®, rješenju koje blokira reklame centralno, bez potrebe za individualnim podešavanjem svakog uređaja. Pi-hole® to postiže drugačijom tehnikom koja se naziva DNS filtriranje. Da bismo razumjeli kako Pi-hole® funkcionira i zašto je ovakav pristup učinkovit, u sljedećem dijelu prvo ćemo se pozabaviti osnovama DNS-a i pojmom DNS filtriranja.
| Slika | Informacije | Dostupnost |
|---|---|---|
 | Pineco 001/198 | Scarlet & Violet Booster Pack |
 | Pineco 001/198  | Scarlet & Violet Booster Pack |
 | Heracross 002/198 | Scarlet & Violet Booster Pack |
 | Heracross 002/198 | Scarlet & Violet Booster Pack |
 | Shroomish 003/198 | Scarlet & Violet Booster Pack |
| Shroomish 003/198 | Scarlet & Violet Booster Pack | |
| Breloom 004/198 | Scarlet & Violet Booster Pack | |
| Breloom 004/198 | Scarlet & Violet Booster Pack | |
| Cacnea 005/198 | Scarlet & Violet Booster Pack | |
| Cacnea 005/198 | Scarlet & Violet Booster Pack | |
| Cacturne 006/198 | Scarlet & Violet Booster Pack | |
| Cacturne 006/198 | Scarlet & Violet Booster Pack | |
| Tropius 007/198 | Scarlet & Violet Booster Pack | |
| Tropius 007/198 | Scarlet & Violet Booster Pack | |
| Scatterbug 008/198 | Scarlet & Violet Booster Pack | |
| Scatterbug 008/198 | Scarlet & Violet Booster Pack | |
| Spewpa 009/198 | Scarlet & Violet Booster Pack | |
| Spewpa 009/198 | Scarlet & Violet Booster Pack | |
| Vivillon 010/198 | Scarlet & Violet Booster Pack | |
| Vivillon 010/198 | Scarlet & Violet Booster Pack | |
| Skiddo 011/198 | Scarlet & Violet Booster Pack | |
| Skiddo 011/198 | Scarlet & Violet Booster Pack | |
| Gogoat 012/198 | Scarlet & Violet Booster Pack | |
| Gogoat 012/198 | Scarlet & Violet Booster Pack | |
| Sprigatito 013/198 | Scarlet & Violet Booster Pack | |
| Sprigatito 013/198 | Scarlet & Violet Booster Pack | |
| Floragato 014/198 | Scarlet & Violet Booster Pack | |
| Floragato 014/198 | Scarlet & Violet Booster Pack | |
| Meowscarada 015/198 | Scarlet & Violet Booster Pack | |
| Meowscarada 015/198 | Scarlet & Violet Booster Pack | |
| Tarountula 016/198 | Scarlet & Violet Booster Pack | |
| Tarountula 016/198 | Scarlet & Violet Booster Pack | |
| Tarountula 017/198 | Scarlet & Violet Booster Pack | |
| Tarountula 017/198 | Scarlet & Violet Booster Pack | |
| Tarountula 018/198 | Scarlet & Violet Booster Pack | |
| Tarountula 018/198 | Scarlet & Violet Booster Pack | |
| Spidops ex 019/198 | Scarlet & Violet Booster Pack | |
| Smoliv 020/198 | Scarlet & Violet Booster Pack | |
| Smoliv 020/198 | Scarlet & Violet Booster Pack | |
| Smoliv 021/198 | Scarlet & Violet Booster Pack | |
| Smoliv 021/198 | Scarlet & Violet Booster Pack | |
| Dolliv 022/198 | Scarlet & Violet Booster Pack | |
| Dolliv 022/198  | Scarlet & Violet Booster Pack | |
| Arboliva 023/198 | Scarlet & Violet Booster Pack | |
| Arboliva 023/198 | Scarlet & Violet Booster Pack | |
| Toedscool 024/198 | Scarlet & Violet Booster Pack | |
| Toedscool 024/198 | Scarlet & Violet Booster Pack | |
| Toedscool 025/198 | Scarlet & Violet Booster Pack | |
| Toedscool 025/198 | Scarlet & Violet Booster Pack | |
| Toedscruel 026/198 | Scarlet & Violet Booster Pack | |
| Toedscruel 026/198 | Scarlet & Violet Booster Pack | |
| Capsakid 027/198 | Scarlet & Violet Booster Pack | |
| Capsakid 027/198 | Scarlet & Violet Booster Pack | |
| Capsakid 028/198 | Scarlet & Violet Booster Pack | |
| Capsakid 028/198 | Scarlet & Violet Booster Pack | |
| Scovillain 029/198 | Scarlet & Violet Booster Pack | |
| Scovillain 029/198 | Scarlet & Violet Booster Pack | |
| Growlithe 030/198 | Scarlet & Violet Booster Pack | |
| Growlithe 030/198 | Growlithe | |
| Growlithe 031/198 | Scarlet & Violet Booster Pack | |
| Growlithe 031/198 | Scarlet & Violet Booster Pack | |
| Arcanine ex 032/198  | Scarlet & Violet Booster Pack | |
| Houndour 033/198 | Scarlet & Violet Booster Pack | |
| Houndour 033/198 | Scarlet & Violet Booster Pack | |
| Houndoom 034/198 | Scarlet & Violet Booster Pack | |
| Houndoom 034/198 | Houndoom | |
| Torkoal 035/198 | Scarlet & Violet Booster Pack | |
| Torkoal 035/198 | Scarlet & Violet Booster Pack | |
| Fuecoco 036/198 | Scarlet & Violet Booster Pack | |
| Fuecoco 036/198 | Scarlet & Violet Booster Pack | |
| Crocalor 037/198 | Scarlet & Violet Booster Pack | |
| Crocalor 037/198 | Scarlet & Violet Booster Pack | |
| Skeledirge 038/198 | Scarlet & Violet Booster Pack | |
| Skeledirge 038/198 | Skeledirge | |
| Charcadet 039/198 | Scarlet & Violet Booster Pack | |
| Charcadet 039/198 | Scarlet & Violet Booster Pack | |
| Charcadet 040/198 | Charcadet | |
| Charcadet 040/198 | Scarlet & Violet Booster Pack | |
| Armarouge 041/198 | Scarlet & Violet Booster Pack | |
| Armarouge 041/198 | Armarouge | |
| Slowpoke 042/198 | Scarlet & Violet Booster Pack | |
| Slowpoke 042/198 | Scarlet & Violet Booster Pack | |
| Slowbro 043/198 | Scarlet & Violet Booster Pack | |
| Slowbro 043/198 | Scarlet & Violet Booster Pack | |
| Magikarp 044/198 | Scarlet & Violet Booster Pack | |
| Magikarp 044/198 | Scarlet & Violet Booster Pack | |
| Gyarados ex 045/198 | Scarlet & Violet Booster Pack | |
| Buizel 046/198 | Scarlet & Violet Booster Pack | |
| Buizel 046/198 | Scarlet & Violet Booster Pack | |
| Floatzel 047/198 | Scarlet & Violet Booster Pack | |
| Floatzel 047/198 | Scarlet & Violet Booster Pack | |
| Alomomola 048/198 | Scarlet & Violet Booster Pack | |
| Alomomola 048/198 | Scarlet & Violet Booster Pack | |
| Clauncher 049/198 | Scarlet & Violet Booster Pack | |
| Clauncher 049/198 | Scarlet & Violet Booster Pack | |
| Clawitzer 050/198 | Scarlet & Violet Booster Pack | |
| Clawitzer 050/198 | Scarlet & Violet Booster Pack | |
| Bruxish 051/198 | Scarlet & Violet Booster Pack | |
| Bruxish 051/198 | Scarlet & Violet Booster Pack | |
| Quaxly 052/198 | Scarlet & Violet Booster Pack | |
| Quaxly 052/198 | Scarlet & Violet Booster Pack | |
| Quaxwell 053/198 | Scarlet & Violet Booster Pack | |
| Quaxwell 053/198 | Scarlet & Violet Booster Pack | |
| Quaquaval 054/198 | Scarlet & Violet Booster Pack | |
| Quaquaval 054/198 | Quaquaval | |
| Wiglett 055/198 | Scarlet & Violet Booster Pack | |
| Wiglett 055/198 | Wiglett | |
| Wiglett 056/198 | Scarlet & Violet Booster Pack | |
| Wiglett 056/198 | Scarlet & Violet Booster Pack | |
| Wugtrio 057/198 | Scarlet & Violet Booster Pack | |
| Wugtrio 057/198 | Scarlet & Violet Booster Pack | |
| Cetoddle 058/198 | Scarlet & Violet Booster Pack | |
| Cetoddle 058/198 | Scarlet & Violet Booster Pack | |
| Cetoddle 059/198 | Scarlet & Violet Booster Pack | |
| Cetoddle 059/198 | Cetoddle | |
| Cetitan 060/198 | Scarlet & Violet Booster Pack | |
| Cetitan 060/198 | Scarlet & Violet Booster Pack | |
| Dondozo 061/198 | Scarlet & Violet Booster Pack | |
| Dondozo 061/198 | Scarlet & Violet Booster Pack | |
| Tatsugiri 062/198 | Scarlet & Violet Booster Pack | |
| Tatsugiri 062/198 | Tatsugiri | |
| Magnemite 063/198 | Scarlet & Violet Booster Pack | |
| Magnemite 063/198 | Scarlet & Violet Booster Pack | |
| Magneton 064/198 | Scarlet & Violet Booster Pack | |
| Magneton 064/198 | Scarlet & Violet Booster Pack | |
| Magnezone ex 065/198 | Scarlet & Violet Booster Pack | |
| Mareep 066/198 | Scarlet & Violet Booster Pack | |
| Mareep 066/198 | Scarlet & Violet Booster Pack | |
| Flaaffy 067/198 | Scarlet & Violet Booster Pack | |
| Flaaffy 067/198 | Flaaffy | |
| Pachirisu 068/198 | Scarlet & Violet Booster Pack | |
| Pachirisu 068/198 | Scarlet & Violet Booster Pack | |
| Rotom 069/198 | Scarlet & Violet Booster Pack | |
| Rotom 069/198 | Scarlet & Violet Booster Pack | |
| Rotom 070/198 | Scarlet & Violet Booster Pack | |
| Rotom 070/198 | Scarlet & Violet Booster Pack | |
| Toxel 071/198 | Scarlet & Violet Booster Pack | |
| Toxel 071/198 | Scarlet & Violet Booster Pack | |
| Toxtricity 072/198 | Scarlet & Violet Booster Pack | |
| Toxtricity 072/198 | Scarlet & Violet Booster Pack | |
| Pawmi 073/198 | Scarlet & Violet Booster Pack | |
| Pawmi 073/198 | Scarlet & Violet Booster Pack | |
| Pawmi 074/198 | Scarlet & Violet Booster Pack | |
| Pawmi 074/198 | Scarlet & Violet Booster Pack | |
| Pawmo 075/198 | Scarlet & Violet Booster Pack | |
| Pawmo 075/198 | Scarlet & Violet Booster Pack | |
| Pawmot 076/198 | Scarlet & Violet Booster Pack | |
| Pawmot 076/198 | Scarlet & Violet Booster Pack | |
| Wattrel 077/198 | Scarlet & Violet Booster Pack | |
| Wattrel 077/198 | Scarlet & Violet Booster Pack | |
| Wattrel 078/198 | Scarlet & Violet Booster Pack | |
| Wattrel 078/198 | Scarlet & Violet Booster Pack | |
| Kilowattrel 079/198 | Scarlet & Violet Booster Pack | |
| Kilowattrel 079/198 | Scarlet & Violet Booster Pack | |
| Miraidon 080/198 | Scarlet & Violet Booster Pack | |
| Miraidon 080/198 | Scarlet & Violet Booster Pack | |
| Miraidon ex 081/198 | Scarlet & Violet Booster Pack | |
| Drowzee 082/198 | Scarlet & Violet Booster Pack | |
| Drowzee 082/198 | Scarlet & Violet Booster Pack | |
| Hypno 083/198 | Scarlet & Violet Booster Pack | |
| Hypno 083/198 | Scarlet & Violet Booster Pack | |
| Ralts 084/198 | Scarlet & Violet Booster Pack | |
| Ralts 084/198 | Scarlet & Violet Booster Pack | |
| Kirlia 085/198 | Scarlet & Violet Booster Pack | |
| Kirlia 085/198 | Scarlet & Violet Booster Pack | |
| Gardevoir ex 086/198 | Scarlet & Violet Booster Pack | |
| Shuppet 087/198 | Scarlet & Violet Booster Pack | |
| Shuppet 087/198 | Scarlet & Violet Booster Pack | |
| Banette ex 088/198 | Scarlet & Violet Booster Pack | |
| Drifloon 089/198 | Scarlet & Violet Booster Pack | |
| Drifloon 089/198 | Scarlet & Violet Booster Pack | |
| Drifblim 090/198 | Scarlet & Violet Booster Pack | |
| Drifblim 090/198 | Scarlet & Violet Booster Pack | |
| Flabébé 091/198 | Scarlet & Violet Booster Pack | |
| Flabébé 091/198 | Scarlet & Violet Booster Pack | |
| Floette 092/198 | Scarlet & Violet Booster Pack | |
| Floette 092/198 | Scarlet & Violet Booster Pack | |
| Florges 093/198 | Scarlet & Violet Booster Pack | |
| Florges 093/198 | Scarlet & Violet Booster Pack | |
| Dedenne 094/198 | Scarlet & Violet Booster Pack | |
| Dedenne 094/198 | Scarlet & Violet Booster Pack | |
| Dedenne 095/198 | Scarlet & Violet Booster Pack | |
| Dedenne 095/198 | Scarlet & Violet Booster Pack | |
| Klefki 096/198 | Scarlet & Violet Booster Pack | |
| Klefki 096/198 | Scarlet & Violet Booster Pack | |
| Fidough 097/198 | Scarlet & Violet Booster Pack | |
| Fidough 097/198 | Scarlet & Violet Booster Pack | |
| Fidough 098/198 | Scarlet & Violet Booster Pack | |
| Fidough 098/198 | Scarlet & Violet Booster Pack | |
| Dachsbun 099/198 | Scarlet & Violet Booster Pack | |
| Dachsbun 099/198 | Scarlet & Violet Booster Pack | |
| Flittle 100/198 | Scarlet & Violet Booster Pack | |
| Flittle 100/198 | Scarlet & Violet Booster Pack | |
| Flittle 101/198 | Scarlet & Violet Booster Pack | |
| Flittle 101/198 | Scarlet & Violet Booster Pack | |
| Flittle 102/198 | Scarlet & Violet Booster Pack | |
| Flittle 102/198 | Scarlet & Violet Booster Pack | |
| Espathra 103/198 | Scarlet & Violet Booster Pack | |
| Espathra 103/198 | Scarlet & Violet Booster Pack | |
| Greavard 104/198 | Scarlet & Violet Booster Pack | |
| Greavard 104/198 | Scarlet & Violet Booster Pack | |
| Greavard 105/198 | Scarlet & Violet Booster Pack | |
| Greavard 105/198 | Scarlet & Violet Booster Pack | |
| Houndstone 106/198 | Scarlet & Violet Booster Pack | |
| Houndstone 106/198 | Scarlet & Violet Booster Pack | |
| Mankey 107/198 | Scarlet & Violet Booster Pack | |
| Mankey 107/198 | Scarlet & Violet Booster Pack | |
| Primeape 108/198 | Scarlet & Violet Booster Pack | |
| Primeape 108/198 | Scarlet & Violet Booster Pack | |
| Annihilape 109/198 | Scarlet & Violet Booster Pack | |
| Annihilape 109/198 | Scarlet & Violet Booster Pack | |
| Meditite 110/198 | Scarlet & Violet Booster Pack | |
| Meditite 110/198 | Scarlet & Violet Booster Pack | |
| Medicham 111/198 | Scarlet & Violet Booster Pack | |
| Medicham 111/198 | Scarlet & Violet Booster Pack | |
| Riolu 112/198 | Scarlet & Violet Booster Pack | |
| Riolu 112/198 | Scarlet & Violet Booster Pack | |
| Riolu 113/198 | Scarlet & Violet Booster Pack | |
| Riolu 113/198 | Scarlet & Violet Booster Pack | |
| Lucario 114/198 | Scarlet & Violet Booster Pack | |
| Lucario 114/198 | Scarlet & Violet Booster Pack | |
| Sandile 115/198 | Scarlet & Violet Booster Pack | |
| Sandile 115/198 | Scarlet & Violet Booster Pack | |
| Krokorok 116/198 | Scarlet & Violet Booster Pack | |
| Krokorok 116/198 | Scarlet & Violet Booster Pack | |
| Krookodile 117/198 | Scarlet & Violet Booster Pack | |
| Krookodile 117/198 | Scarlet & Violet Booster Pack | |
| Hawlucha 118/198 | Scarlet & Violet Booster Pack | |
| Hawlucha 118/198 | Scarlet & Violet Booster Pack | |
| Silicobra 119/198 | Scarlet & Violet Booster Pack | |
| Silicobra 119/198 | Scarlet & Violet Booster Pack | |
| Sandaconda 120/198 | Scarlet & Violet Booster Pack | |
| Sandaconda 120/198 | Scarlet & Violet Booster Pack | |
| Stonjourner 121/198 | Scarlet & Violet Booster Pack | |
| Stonjourner 121/198 | Scarlet & Violet Booster Pack | |
| Klawf 121/198 | Scarlet & Violet Booster Pack | |
| Klawf 122/198 | Scarlet & Violet Booster Pack | |
| Great Tusk ex 123/198 | Scarlet & Violet Booster Pack | |
| Koraidon 124/198 | Scarlet & Violet Booster Pack | |
| Koraidon 124/198 | Scarlet & Violet Booster Pack | |
| Koraidon ex 125/198 | Scarlet & Violet Booster Pack | |
| Grimer 126/198 | Scarlet & Violet Booster Pack | |
| Grimer 126/198 | Scarlet & Violet Booster Pack | |
| Muk 127/198 | Scarlet & Violet Booster Pack | |
| Muk 127/198 | Scarlet & Violet Booster Pack | |
| Seviper 128/198 | Scarlet & Violet Booster Pack | |
| Seviper 128/198 | Scarlet & Violet Booster Pack | |
| Spiritomb 129/198 | Scarlet & Violet Booster Pack | |
| Spiritomb 129/198 | Scarlet & Violet Booster Pack | |
| Croagunk 130/198 | Scarlet & Violet Booster Pack | |
| Croagunk 130/198 | Scarlet & Violet Booster Pack | |
| Toxicroak ex 131/198 | Scarlet & Violet Booster Pack | |
| Pawniard 132/198 | Scarlet & Violet Booster Pack | |
| Pawniard 132/198 | Scarlet & Violet Booster Pack | |
| Bisharp 133/198 | Scarlet & Violet Booster Pack | |
| Bisharp 133/198 | Scarlet & Violet Booster Pack | |
| Kingambit 134/198 | Scarlet & Violet Booster Pack | |
| Kingambit 134/198 | Scarlet & Violet Booster Pack | |
| Maschiff 135/198  | Scarlet & Violet Booster Pack | |
| Maschiff 135/198 | Scarlet & Violet Booster Pack | |
| Maschiff 136/198 | Scarlet & Violet Booster Pack | |
| Maschiff 136/198 | Scarlet & Violet Booster Pack | |
| Mabosstiff 137/198 | Scarlet & Violet Booster Pack | |
| Mabosstiff 137/198 | Scarlet & Violet Booster Pack | |
| Bombirdier 138/198 | Scarlet & Violet Booster Pack | |
| Bombirdier 138/198 | Scarlet & Violet Booster Pack | |
| Forretress 139/198 | Scarlet & Violet Booster Pack | |
| Forretress 139/198 | Scarlet & Violet Booster Pack | |
| Varoom 140/198 | Scarlet & Violet Booster Pack | |
| Varoom 140/198 | Scarlet & Violet Booster Pack | |
| Varoom 141/198 | Scarlet & Violet Booster Pack | |
| Varoom 141/198 | Scarlet & Violet Booster Pack | |
| Revavroom 142/198 | Scarlet & Violet Booster Pack | |
| Revavroom 142/198 | Scarlet & Violet Booster Pack | |
| Iron Threads ex 143/198 | Scarlet & Violet Booster Pack | |
| Chansey 144/198 | Scarlet & Violet Booster Pack | |
| Chansey 144/198 | Scarlet & Violet Booster Pack | |
| Blissey 145/198 | Scarlet & Violet Booster Pack | |
| Blissey 145/198 | Scarlet & Violet Booster Pack | |
| Zangoose 146/198 | Scarlet & Violet Booster Pack | |
| Zangoose 146/198 | Scarlet & Violet Booster Pack | |
| Zangoose 147/198 | Scarlet & Violet Booster Pack | |
| Zangoose 147/198 | Scarlet & Violet Booster Pack | |
| Starly 148/198 | Scarlet & Violet Booster Pack | |
| Starly 148/198 | Scarlet & Violet Booster Pack | |
| Staravia 149/198 | Scarlet & Violet Booster Pack | |
| Staravia 149/198 | Scarlet & Violet Booster Pack | |
| Staraptor 150/198 | Scarlet & Violet Booster Pack | |
| Staraptor 150/198 | Scarlet & Violet Booster Pack | |
| Skwovet 151/198 | Scarlet & Violet Booster Pack | |
| Skwovet 151/198 | Scarlet & Violet Booster Pack | |
| Greedent 152/198 | Scarlet & Violet Booster Pack | |
| Greedent 152/198 | Scarlet & Violet Booster Pack | |
| Indeedee 153/198 | Scarlet & Violet Booster Pack | |
| Indeedee 153/198 | Scarlet & Violet Booster Pack | |
| Lechonk 154/198 | Scarlet & Violet Booster Pack | |
| Lechonk 154/198 | Scarlet & Violet Booster Pack | |
| Lechonk 155/198 | Scarlet & Violet Booster Pack | |
| Lechonk 155/198 | Scarlet & Violet Booster Pack | |
| Lechonk 156/198 | Scarlet & Violet Booster Pack | |
| Lechonk 156/198 | Scarlet & Violet Booster Pack | |
| Oinkologne 157/198 | Scarlet & Violet Booster Pack | |
| Oinkologne 157/198 | ||
| Oinkologne ex 158/198 | Scarlet & Violet Booster Pack | |
| Tandemaus 159/198 | Scarlet & Violet Booster Pack | |
| Tandemaus 159/198 | Scarlet & Violet Booster Pack | |
| Tandemaus 160/198 | Scarlet & Violet Booster Pack | |
| Tandemaus 160/198 | Scarlet & Violet Booster Pack | |
| Maushold 161/198 | Scarlet & Violet Booster Pack | |
| Maushold 161/198 | Scarlet & Violet Booster Pack | |
| Squawkabilly 162/198 | Scarlet & Violet Booster Pack | |
| Squawkabilly 162/198 | Scarlet & Violet Booster Pack | |
| Cyclizar 163/198 | Scarlet & Violet Booster Pack | |
| Cyclizar 163/198 | Scarlet & Violet Booster Pack | |
| Cyclizar 164/198 | Scarlet & Violet Booster Pack | |
| Cyclizar 164/198 | Scarlet & Violet Booster Pack | |
| Flamigo 165/198 | Scarlet & Violet Booster Pack | |
| Flamigo 165/198 | Scarlet & Violet Booster Pack | |
| Arven 166/198 | Scarlet & Violet Booster Pack | |
| Arven 166/198 | Scarlet & Violet Booster Pack | |
| Beach Court 167/198 | Scarlet & Violet Booster Pack | |
| Beach Court 167/198 | Scarlet & Violet Booster Pack | |
| Crushing Hammer 168/198 | Scarlet & Violet Booster Pack | |
| Crushing Hammer 168/198 | Scarlet & Violet Booster Pack | |
| Defiance Band 169/198 | Scarlet & Violet Booster Pack | |
| Defiance Band 169/198 | Scarlet & Violet Booster Pack | |
| Electric Generator 170/198 | Scarlet & Violet Booster Pack | |
| Electric Generator 170/198 | Scarlet & Violet Booster Pack | |
| Energy Retrieval 171/198 | Scarlet & Violet Booster Pack | |
| Energy Retrieval 171/198 | Scarlet & Violet Booster Pack | |
| Energy Search 172/198 | Scarlet & Violet Booster Pack | |
| Energy Search 172/198 | Scarlet & Violet Booster Pack | |
| Energy Switch 173/198 | Scarlet & Violet Booster Pack | |
| Energy Switch 173/198 | Scarlet & Violet Booster Pack | |
| Exp. Share 174/198 | Scarlet & Violet Booster Pack | |
| Exp. Share 174/198 | Scarlet & Violet Booster Pack | |
| Jacq 175/198 | Scarlet & Violet Booster Pack | |
| Jacq 175/198 | Scarlet & Violet Booster Pack | |
| Judge 176/198 | Scarlet & Violet Booster Pack | |
| Judge 176/198 | Scarlet & Violet Booster Pack | |
| Katy 177/198 | Scarlet & Violet Booster Pack | |
| Katy 177/198 | Scarlet & Violet Booster Pack | |
| Mesagoza 178/198 | Scarlet & Violet Booster Pack | |
| Mesagoza 178/198 | Scarlet & Violet Booster Pack | |
| Miriam 179/198 | Scarlet & Violet Booster Pack | |
| Miriam 179/198 | Scarlet & Violet Booster Pack | |
| Nemona 180/198 | Scarlet & Violet Booster Pack | |
| Nemona 180/198 | Scarlet & Violet Booster Pack | |
| Nest Ball 181/198 | Scarlet & Violet Booster Pack | |
| Nest Ball 181/198 | Scarlet & Violet Booster Pack | |
| Pal Pad 182/198 | Scarlet & Violet Booster Pack | |
| Pal Pad 182/198 | Scarlet & Violet Booster Pack | |
| Penny 183/198 | Scarlet & Violet Booster Pack | |
| Penny 183/198 | Scarlet & Violet Booster Pack | |
| Picnic Basket 184/198 | Scarlet & Violet Booster Pack | |
| Picnic Basket 184/198 | Scarlet & Violet Booster Pack | |
| Poké Ball 185/198 | Scarlet & Violet Booster Pack | |
| Poké Ball 185/198 | Scarlet & Violet Booster Pack | |
| Pokégear 3.0 186/198 | Scarlet & Violet Booster Pack | |
| Pokégear 3.0 186/198 | Scarlet & Violet Booster Pack | |
| Pokémon Catcher 187/198 | Scarlet & Violet Booster Pack | |
| Pokémon Catcher 187/198 | Scarlet & Violet Booster Pack | |
| Potion 188/198 | Scarlet & Violet Booster Pack | |
| Potion 188/198 | Scarlet & Violet Booster Pack | |
| Professor’s Research [Professor Sada] 189/198 | Scarlet & Violet Booster Pack | |
| Professor’s Research [Professor Sada] 189/198 | Scarlet & Violet Booster Pack | |
| Professor’s Research [Professor Turo] 190/198 | Scarlet & Violet Booster Pack | |
| Professor’s Research [Professor Turo] 190/198 | Scarlet & Violet Booster Pack | |
| Rare Candy 191/198 | Scarlet & Violet Booster Pack | |
| Rare Candy 191/198 | Scarlet & Violet Booster Pack | |
| Rock Chestplate 192/198 | Scarlet & Violet Booster Pack | |
| Rock Chestplate 192/198 | Scarlet & Violet Booster Pack | |
| Rocky Helmet 193/198 | Scarlet & Violet Booster Pack | |
| Rocky Helmet 193/198 | Scarlet & Violet Booster Pack | |
| Switch 194/198 | Scarlet & Violet Booster Pack | |
| Switch 194/198 | Scarlet & Violet Booster Pack | |
| Team Star Grunt 195/198 | Scarlet & Violet Booster Pack | |
| Team Star Grunt 195/198 | Scarlet & Violet Booster Pack | |
| Ultra Ball 196/198 | Scarlet & Violet Booster Pack | |
| Ultra Ball 196/198 | Scarlet & Violet Booster Pack | |
| Vitality Bend 197/198 | Scarlet & Violet Booster Pack | |
| Vitality Band 197/198 | Scarlet & Violet Booster Pack | |
| Youngster 198/198 | Scarlet & Violet Booster Pack | |
| Youngster 198/198 | Scarlet & Violet Booster Pack | |
| Tarountula 199/198 | Scarlet & Violet Booster Pack | |
| Dolliv 200/198 | Scarlet & Violet Booster Pack | |
| Toedscool 201/198 | Scarlet & Violet Booster Pack | |
| Scovillain 202/198 | Scarlet & Violet Booster Pack | |
| Armarouge 203/198 | Scarlet & Violet Booster Pack | |
| Slowpoke 204/198 | Scarlet & Violet Booster Pack | |
| Clauncher 205/198 | Scarlet & Violet Booster Pack | |
| Wiglett 206/198 | Scarlet & Violet Booster Pack | |
| Dondozo 207/198 | Scarlet & Violet Booster Pack | |
| Pachirisu 208/198 | Scarlet & Violet Booster Pack | |
| Pawmot 209/198 | Scarlet & Violet Booster Pack | |
| Drowzee 210/198 | Scarlet & Violet Booster Pack | |
| Ralts 211/198 | Scarlet & Violet Booster Pack | |
| Kirlia 212/198 | Scarlet & Violet Booster Pack | |
| Fidough 213/198 | Scarlet & Violet Booster Pack | |
| Greavard 214/198 | Scarlet & Violet Booster Pack | |
| Riolu 215/198 | Scarlet & Violet Booster Pack | |
| Sandile 216/198 | Scarlet & Violet Booster Pack | |
| Klawf 217/198 | Scarlet & Violet Booster Pack | |
| Mabosstiff 218/198 | Scarlet & Violet Booster Pack | |
| Bombirdier 219/198 | Scarlet & Violet Booster Pack | |
| Kingambit 220/198 | Scarlet & Violet Booster Pack | |
| Starly 221/198 | Scarlet & Violet Booster Pack | |
| Skwovet 222/198 | Scarlet & Violet Booster Pack | |
| Spidops ex 223/198 | Scarlet & Violet Booster Pack | |
| Arcanine ex 224/198 | Scarlet & Violet Booster Pack | |
| Gyarados ex 225/198 | Scarlet & Violet Booster Pack | |
| Magnezone ex 226/198 | Scarlet & Violet Booster Pack | |
| Miraidon ex 227/198 | Scarlet & Violet Booster Pack | |
| Gardevoir ex 228/198 | Scarlet & Violet Booster Pack | |
| Banette ex 229/198 | Scarlet & Violet Booster Pack | |
| Great Tusk ex 230/198 | Scarlet & Violet Booster Pack | |
| Koraidon ex 231/198 | Scarlet & Violet Booster Pack | |
| Toxicroak ex 232/198 | Scarlet & Violet Booster Pack | |
| Iron Treads ex 233/198 | Scarlet & Violet Booster Pack | |
| Oinkologne ex 234/198 | Scarlet & Violet Booster Pack | |
| Arven 235/198 | Scarlet & Violet Booster Pack | |
| Jacq 236/198 | Scarlet & Violet Booster Pack | |
| Katy 237/198 | Scarlet & Violet Booster Pack | |
| Miriam 238/198 | Scarlet & Violet Booster Pack | |
| Penny 239/198 | Scarlet & Violet Booster Pack | |
| Professor’s Research [Professor Sada] 240/198 | Scarlet & Violet Booster Pack | |
| Professor’s Research [Professor Turo] 241/198 | Scarlet & Violet Booster Pack | |
| Team Star Grunt 242/198 | Scarlet & Violet Booster Pack | |
| Spidops ex 243/198 | Scarlet & Violet Booster Pack | |
| Miraidon ex 244/198 | Scarlet & Violet Booster Pack | |
| Gardevoir ex 245/198 | Scarlet & Violet Booster Pack | |
| Great Tusk ex 246/198 | Scarlet & Violet Booster Pack | |
| Koraidon ex 247/198 | Scarlet & Violet Booster Pack | |
| Iron Treads ex 248/198 | Scarlet & Violet Booster Pack | |
| Arven 249/198 | Scarlet & Violet Booster Pack | |
| Jacq 250/198 | Scarlet & Violet Booster Pack | |
| Miriam 251/198 | Scarlet & Violet Booster Pack | |
| Penny 252/198 | Scarlet & Violet Booster Pack | |
| Miraidon ex 253/198 | Scarlet & Violet Booster Pack | |
| Koraidon ex 254/198 | Scarlet & Violet Booster Pack | |
| Nest Ball 255/198 | Scarlet & Violet Booster Pack | |
| Rare Candy 256/198 | Scarlet & Violet Booster Pack | |
| Basic Lightning Energy 257/198 | Scarlet & Violet Booster Pack | |
| Basic Fighting Energy 258/198 | Scarlet & Violet Booster Pack |
Java platforma i jezik su započeti kao interni istraživački projekt tvrtke Sun Microsystems u prosincu 1990., iako je srž ideje nastala nekoliko godina ranije.
Projekt NeWS
Sve je započeo James Gosling koji pokrenuo projekt nazvan NeWS (Network/extensible Window System). Ideja projekta NeWS je bila napraviti softver koji omogućava kreiranje prozora (engl. windows) u grafičkom korisničkom sustavu, na bilo kojem računalu, bez obzira o kojem proizvođaču se radi, Sun, Hewlett-Packard, IBM i sl. To je u to vrijeme bio veliki problem jer su grafička sučelja uzimala sve više trakcije, i svaki proizvođač računala je imao svoj softver za crtanje prozora, što je značilo da je svaki komercijalni softver morao biti posebno rađen za svakog proizvođača jer je morao implementirati njegov set standarda za crtanje prozora. Sun je planirao izdavati licence za NeWS proizvođačima računala dok tehnologija ne postaje industrijski standard. Takvo što bi učvrstilo poziciju Suna kao tehnološkog predvodnika što bi kompaniju učinilo privlačnijom potrošačima. Kompanija je službeno lansirala NeWS na Comdex sajmu u Atlanti na proljeće 1987., te krenula u potragu za partnerima. Prethodni proizvod tvrtke Sun, NFS (Network File System), je bio iznimno uspješan te je postavio industrijski standard koje su ostale kompanije morale slijediti. Ta činjenica je rezultirala velikim otporom NeWS-u, te kompanija nije uspjela ostvariti željena partnerstva kako bi ga probila na željeni dio tržišta, zbog čega je u konačnici projekt propao. Na sreću NeWS nije bio totalni gubitak za Sun. Srž NeWS-a, izvršavanje neovisno o hardveru, ponovno će se roditi u Javi nekoliko godina kasnije.1
Tajni projekt Green
Krajem 1990. na scenu stupa Patrick Naughton, tada dvadesetpetogodišnji ambiciozni programer, Patrick je bio nezadovoljan smjerom kojim je kompanija krenula. Napuštanjem projekta NeWS, programeri koji su radili na njemu su premješteni na druga istraživačka mjesta, ali kompanija je djelovala uspavano, nije bilo drugih značajnih projekata. To je Patricka natjeralo da potraži novi posao, te je dobio priliku pridružiti se kompaniji Next koju je osnovao Steve Jobs. Iako je prošao sve intervjue i bio primljen u kompaniju, ipak nije mogao samo tako otići bez da to kaže Scottu McNealyu, CEO-u Sun Microsystemsa. Nakon razgovora, Scott mu je rekao da se pretvara da je Bog i pošalje mu e-mail s popisom stvari koje ne valjaju u kompaniji, s prijedlozima kako ih popraviti. To je bio vrlo dobar potez jer je Patrick napisao poduži e-mail u kojem je iznio sve svoje frustracije, još iz vremena NeWS projekta. Ono što je Patrick zamislio je malu usko povezanu grupu ljudi koja će raditi brzo bez birokracije i opozicije. Scott je proslijedio e-mail ključnim ljudima u kompaniji koji je u konačnici pronašao put do Jamesa Goslinga. James je instantno prepoznao iskru te krenuo u akciju. Upoznao ga je sa Mike Sheridanom te je oformljen tim ljudi koji su danas poznati kao začetnici Jave, James Gosling, Patrick Naughton i Mike Sheridan. Projekt je ubrzo dobio ime Green, a poslovni plan je nazvan “Iza zelenih vrata”, po najpopularnijem pornografsku filmu u tom vremenu. Kako bi osigurali nesmetan rad i otklonili birokratske probleme, projekt je rađen u tajnosti, te su za njega znali samo najviši rukovodioci kompanije.2
Tim je originalno razmišljao o nadogradnji postojećeg C++ jezika, međutim odustali su od te ideje zbog više razloga. Zbog toga što su razvijali jezik za embedded sustave koji imaju ograničene resurse, zaključili su da C++ zahtjeva previše memorije. Jezik također nije imao sakupljač smeća (engl. Garbage collector), što je značilo da programeri moraju ručno upravljati sistemskom memorijom, što je izazovan zadatak koji često dovodi do problema.
Gosling je probao modificirati i proširiti C++ (nazivajući ga C++ ++ –), međutim ubrzo napušta tu ideju i stvara novi programski jezik, kojeg naziva Oak (hrv. hrast), po drvetu kojeg je imao ispred ureda.
Zeleni projekt u jednom trenutku postaje Firstperson. Tim koji je radio na Firstpersonu je htio napraviti interaktivni uređaj za upravljanje televizijom, međutim televizijska industrija nije bila previše zainteresirana jer su korisnicima dali previše slobode. Ubrzo cijeli projekt Firstperson propada.
1993. godine, naglo započinje razvoj World Wide Weba i ljudi iz Suna uuočavaju veliki potencijal Jave u tome području. Naughton izrađuje mali web preglednik pod nazivom WebRunner, kasnije preimenovan u HotJava 1995. Java je omogućavala dodavanje dinamičkih interaktivnih sadržaja i animacija na internetske stranice.
U listopadu 1994. Sun mijenja naziv jezika u Java, zbog toga što je već postojala tvrtka Oak Technologies. Iako je bilo moguće preuzimanje Java 1.0a verzije 1994. godine, prva službena verzija Jave pod imenom Java 1.0a2 je objavljenja 23. svibnja 1995. na SunWorld konferenciji.
2009. godine Oracle preuzima Sun Microsystems.
18.03.2014. Sun Microsystems objavljuje inačicu Java 8.
Reference
- Southwick, Karen (1999). High Noon: the inside story of Scott McNealy and the rise of Sun Microsystems. New York [u.a.]: Wiley. pp. 72–74. ISBN 0471297135. ↩︎
- Southwick, Karen (1999). High Noon: the inside story of Scott McNealy and the rise of Sun Microsystems. New York [u.a.]: Wiley. pp. 123–124. ISBN 0471297135. ↩︎